前两天,有个朋友想爬取个公众号(所有标题+日期+链接),问我能不能用爬虫搞定。
之前,我本来用Python程序搞定。后来发现,只爬取这些内容,完全可以用过去介绍过的爬虫插件来搞定。
刚好还有些常用技巧,之前的教程中没介绍到,所以干脆写一篇教程。
按照我们之前“先用后学”的惯例,先看看“成品”长什么样。
1.
先用
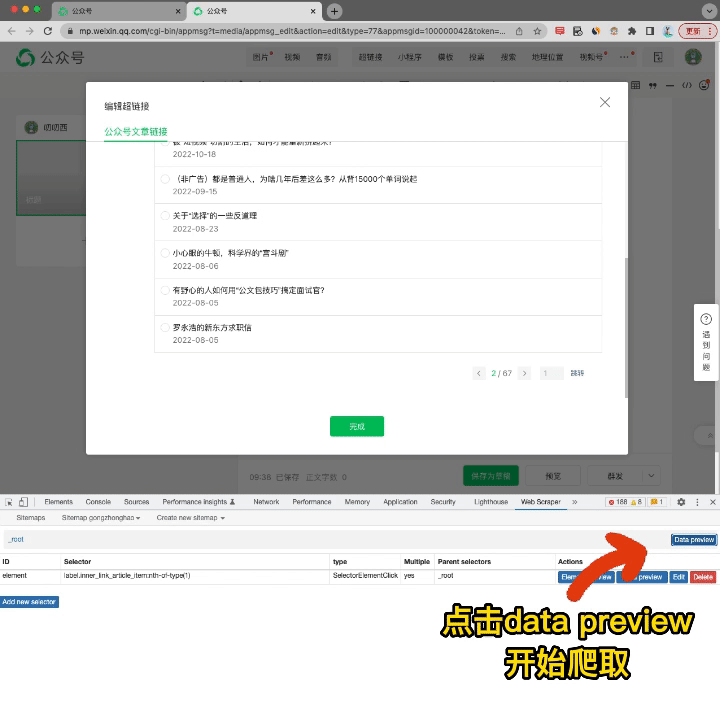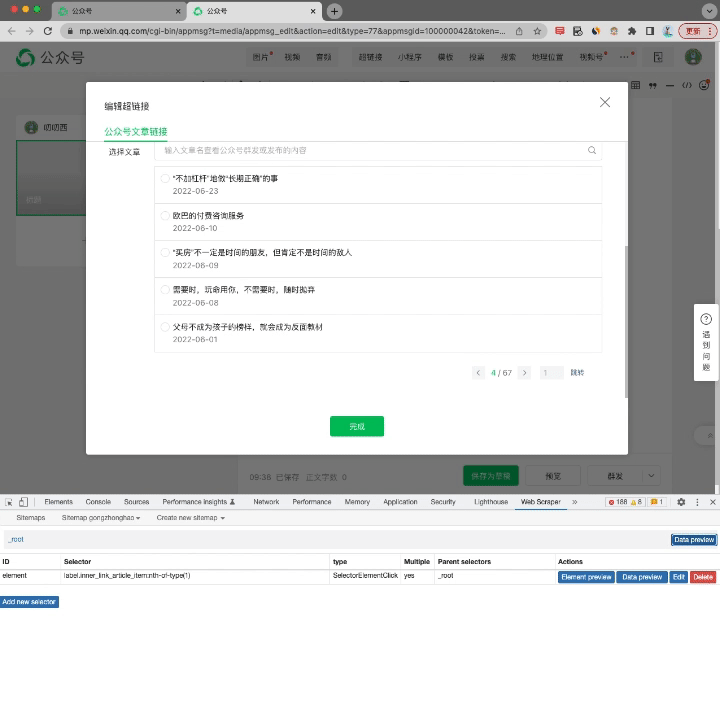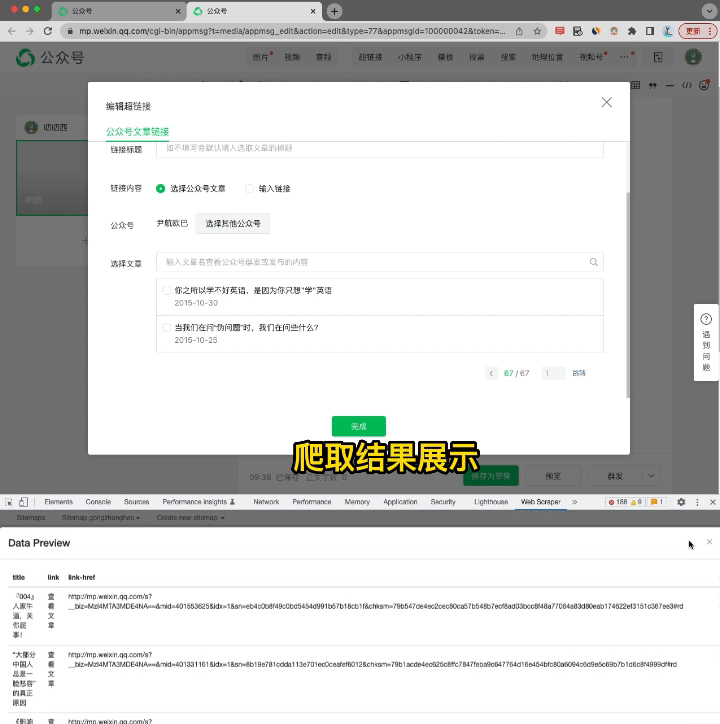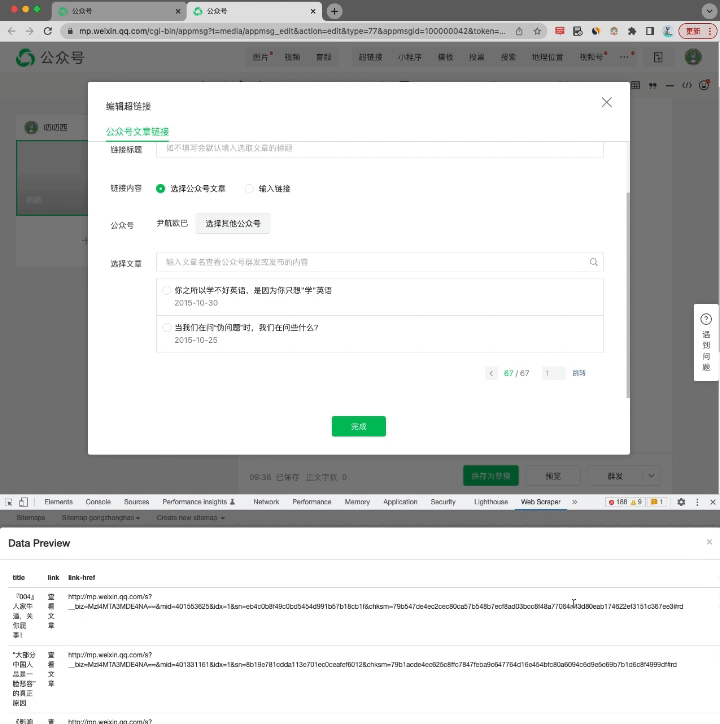
这里有一个页面,通过公号名称,可以找到任意一个公众号,里面会显示发布过的所有文章(文章标题,发布时间,文章链接)
至于这个页面是如何获取的,后面会讲到,大家先继续阅读。
有了这个页面之后,其实就回到了之前学习的《多页爬取》问题了。
不熟悉这个系列教程的朋友,可以看这几篇文章,后面的操作只会给出关键环节,不会像基础教程那么面面俱到。
首先,建立一个sitemap,用于制定爬取规则。
进入到主界面之后,首先建立一个selector,把所有的“重复单元”都选出来(尽量包含每个元素)。由于需要翻页,所以我们选择element click这个类型。

注意:当选择click对象时,不要选择第1页当中的“下一页”按钮,而要翻到第2页,在里面选择“下一页”按钮(原因后面会解释)
选择好之后,点击保存,这样我们就获得了包含标题、日期、链接的“重复单元”了。
下面就是进入到“重复单元”里,选出每个具体的爬取对象了。
选择标题

选择日期
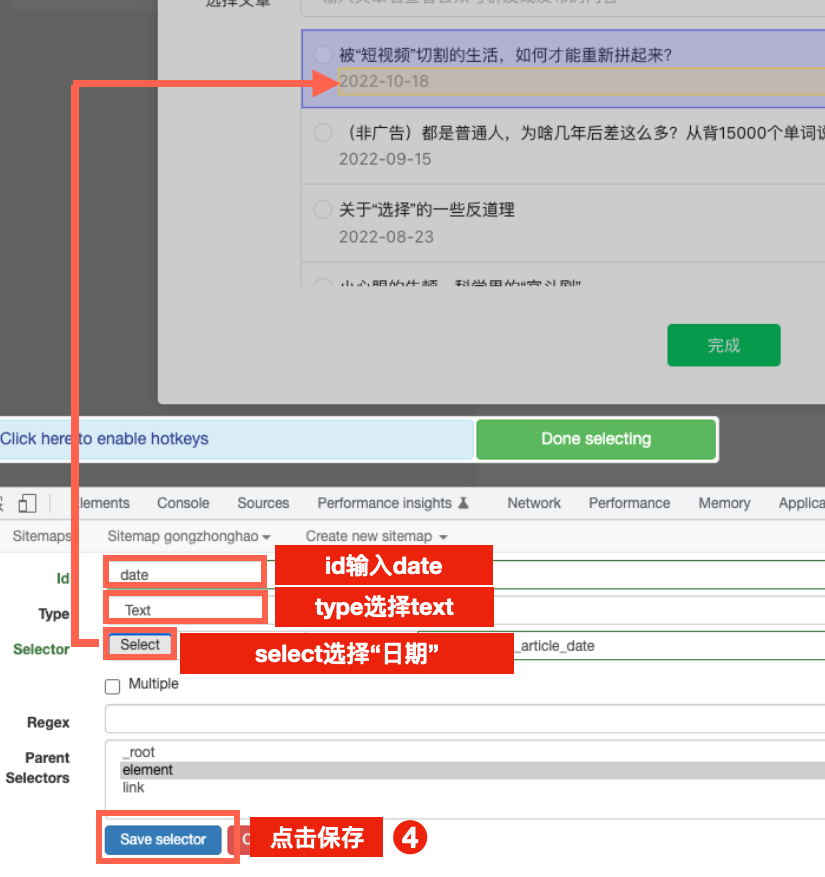
选择文章链接(注意是link)
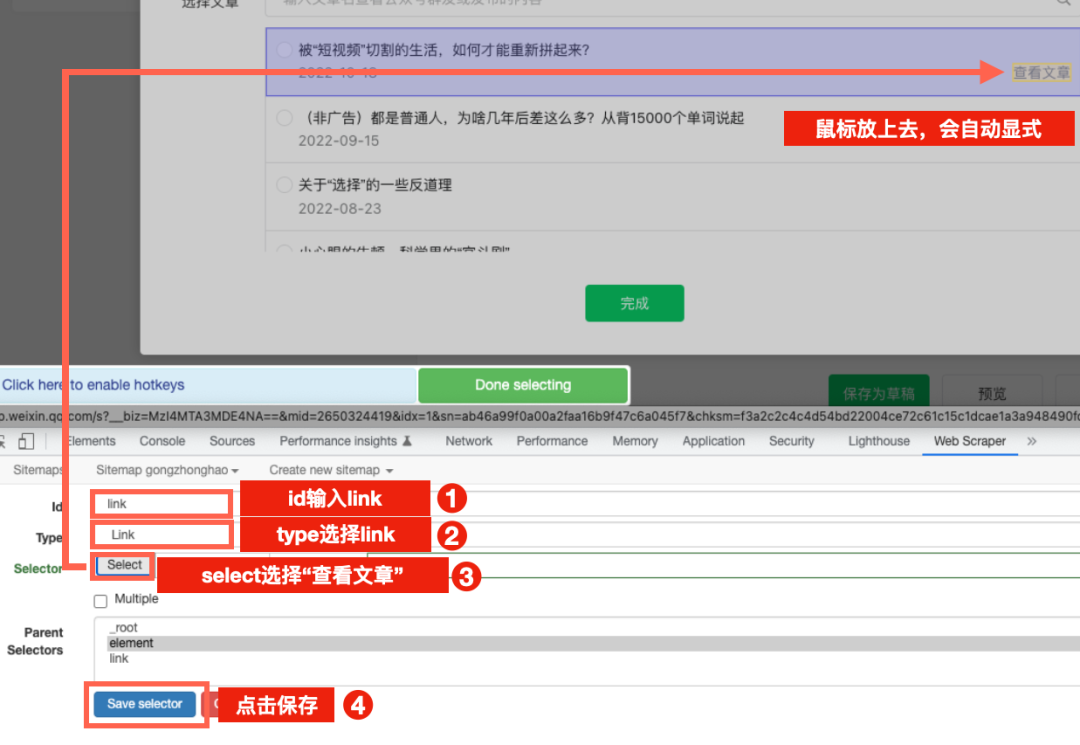
完成这些选取之后,就可以开始爬取了。不过这里不要去点击“Scrape”按钮,否则会失败。

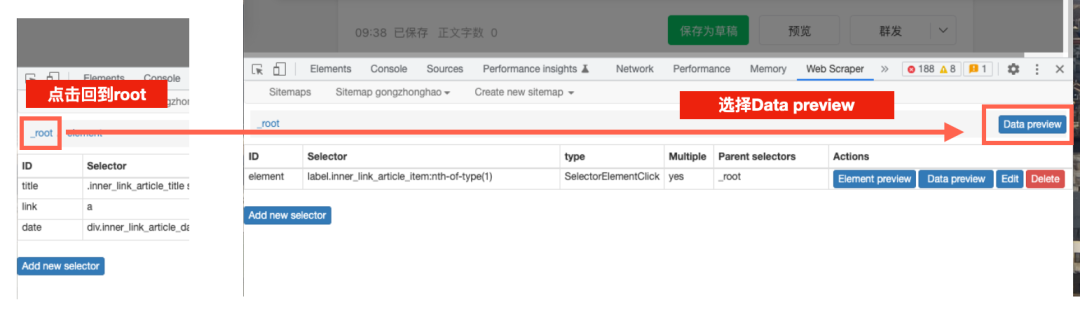
而是要退回爬取的根目录,然后点击那里的Data Preview选项。

这时就能看到,网页按照我们之前的设定,被一页页翻过,等到翻到最后一页时,下方会自动弹出所有爬取到的内容了。

我们可以全选这些内容,粘贴到excel表格中。

以上就完成了公众号基础数据的爬取。
下面解释一下几个需要注意的细节。
2.
后学
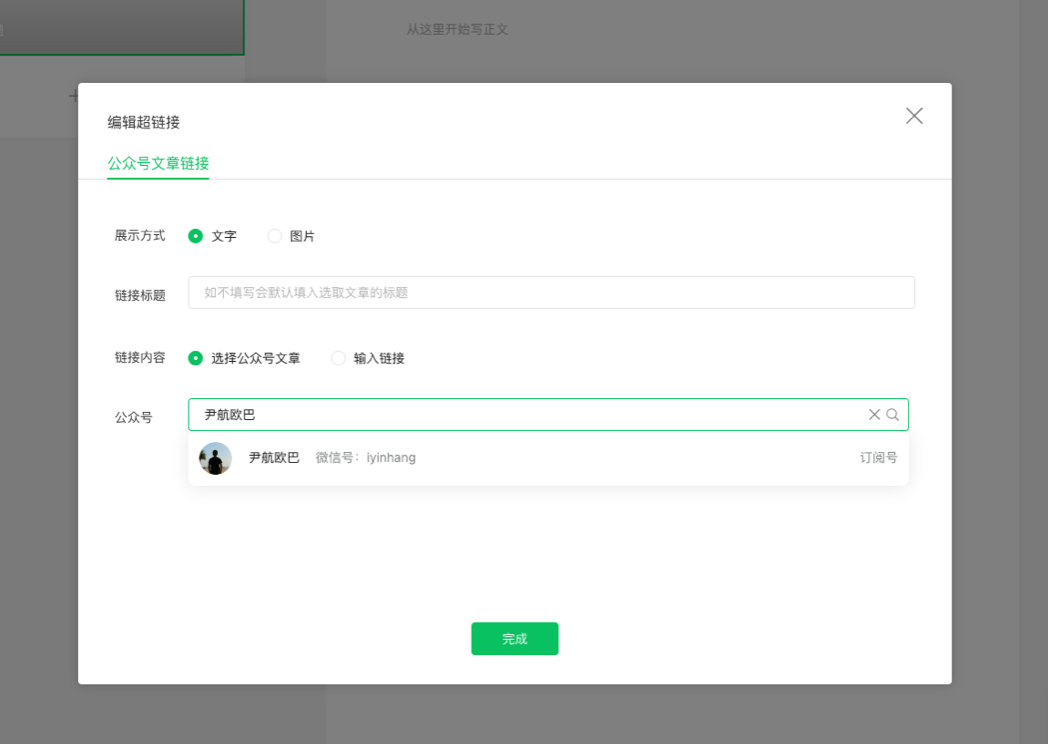
首先说下爬取的页面。它能选所有公众号,并且看到往期文章,这个东西是哪来的?
答案:公众号的后台系统。

我们看到的公众号文章,都是作者在后台写好之后发布的。
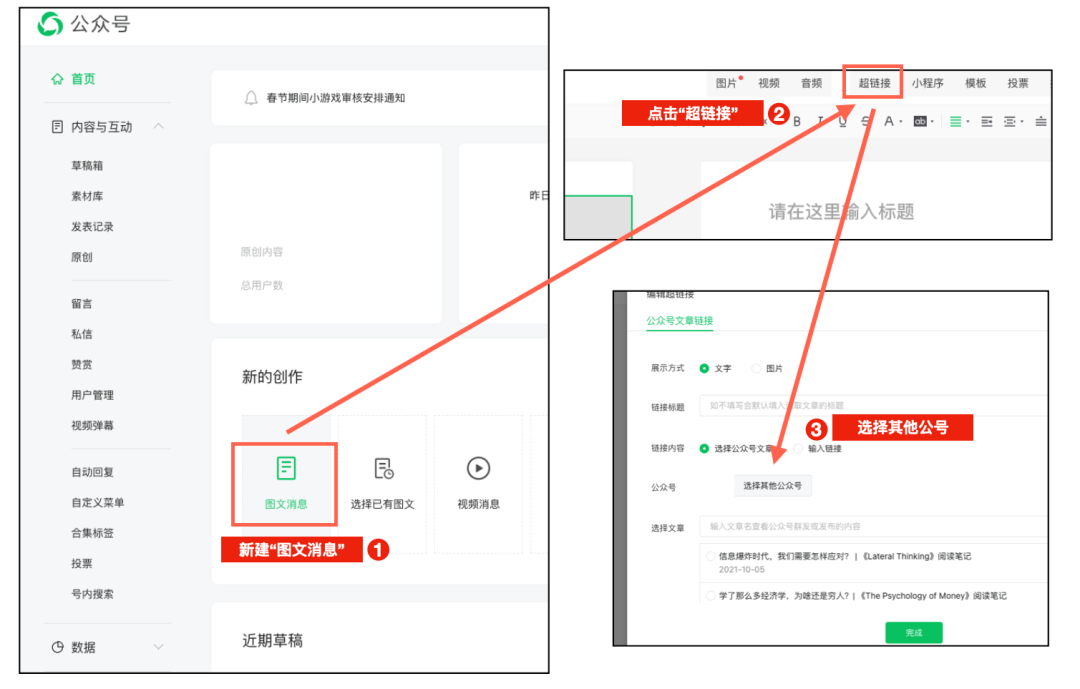
而在写文章时,除了能做加粗斜体等变化之外,还可以在文章中通过超链接,插入其他文章链接(自己的/他人的)

由于公众号内部是打通的,所以通过这个超链接按钮,我们可以访问所有公众号,拿到所有文章链接。
而这个选取的页面,就可以成为我们爬取的起点。

这也是为啥我们用“data preview”,而不是之前的“scrape”来进行爬取。
因为这个页面本身是一个“弹窗”,按照之前的方法爬取,这个页面会消失,我们针对“弹窗”设定的爬取规则也就全都失效了。

下一个问题是:为啥要从第2页开始爬取?
答案:从第2页开始,才能看到“完整”的翻页按钮。
当我们选择element click当中的click标签时,是希望选中“下一页”这个按钮,以便它帮我们不停翻页,直到最后一页。
如果我们选中了“第一页”的按钮,它对应的标签是a.weui-desktop-btn_mini。
这个标签在后面的页面中,其实代表了两个按钮。这一点可以通过在第二页中,点击element preview来查看(下图所示)


这时,程序会默认选取第一个按钮,也就是“上一页”按钮。
这样就会出现一个现象。爬虫爬取完第1页,然后点击click绑定的按钮(这时是“下一页”),跳转到第2页。爬取完第2页,点击按钮(这时是“上一页”),重新回到第1页,然后重复循环。

所以我们要从第二页开始选取按钮。这时也能看到,选取的标签中,带有一个(2),因为翻页按钮有两个,而我们要选择的“下一页”是其中的第二个。

由于从第2页到最后的“下一页”标签都一样,所以就不会出现“反复横跳”的问题了。
那么问题来了:第1页怎么办?
答案:把 element click 改成 element
当我们爬取完所有的内容之后,可以重新回到第1页,把爬取类型修改一下,然后data preview一下,把这一页的内容单独爬取出来。

3.
补充
1.访问限制
公众号后台有保护机制,如果翻页过多,会限制当天访问,第二天会恢复。所以不建议大家一次爬取太多页面。

另外翻页的速度也不要太快,这样也可能触发访问限制,element click当中的默认设置即可。
2.链接内爬取
学过之前教程的朋友,可能还记得,爬取到的链接,还可以进入之后,继续爬去里面的内容(链接内爬取)

但这个选项在这里不适用。
所以如果你还想爬取链接内部的文章,暂时无法用这个工具一次搞定。
不过话说回来,链接都得到了,最困难的一步已经完成了,后面就是用其他工具,批量进入链接当中,爬取相应的内容了。
如果后期找到了简单有效的方法,我会再写一篇教程分享给大家。
以上是教程的所有内容,看完之后想要尝试的朋友,只需要注册一个自己的公众号。
我在百度查了一下,腾讯自己就有一个完整的注册流程介绍:

选择注册里面的“订阅号”即可,这个注册起来最方便。
随后登录到自己的公众号后台,点击“新建文章”,点击工具栏当中的“超链接”,输入自己想爬取的公众号,找到文章页面,就可以从教程第一步开始操作了。


这篇文章是2023年写的,后期公众号的后台可能还会改版,在那之前,这个方法应该都是适用的。
掌握了web scraper之后,关键是找到目标爬取页,这样就又回到了基础教程中的场景,利用已有的技术就能解决了。
这让我想到一个故事:数学家泡茶。
数学家泡茶有一个固定流程:找个空水壶,装满水,把水烧开,找个空杯子,放茶叶,倒开水,等茶泡好。
当他拿到一个水壶,但发现里面已经装满水时,他会直接跳到“烧水”那一步么?
不会。
他会把水倒掉,然后重新从“找个空水壶”那一步开始。
这么做看似木讷,不知变通,但我挺喜欢它背后的思想:
把新问题变成老问题。
碰到新问题,比起重新找答案,数学家更喜欢看看它和之前的问题有什么相似点,能不能还原成老问题,然后用已有的方法解决它。
至于优化已有的解决方案,那是后面要做的事情,当下最关键的,还是先把问题解决掉。
上一篇:反道理补遗(2)