上一篇我们学习了单页的基本爬取方法。
核心流程就三点:
1.确定目标网站,新建一个“网页地图”2.根据想爬取的内容,选出所有“重复单元”3.在单元内选择具体数据,实现批量爬取
之前我们只爬取了一个内容,这次我们试着同时爬取多个内容,并且把链接内部的内容也爬取出来。
多数据爬取流程(先用)
建议大家先看一下“视频版”的演示,然后再用“图文版”进行分布操作
这部分教程是上篇教程的延续,默认大家已经完成上篇的内容。
如果你在上篇教程中,已经创建好了针对“豆瓣电影排行榜”的网页地图,只需要在Web Scraper的主界面中,点击第一栏的“sitemaps”然后选择已创建的地图即可。
如果你还没有完成上篇的内容,建议回到上篇完成之后,再来看这部分内容。
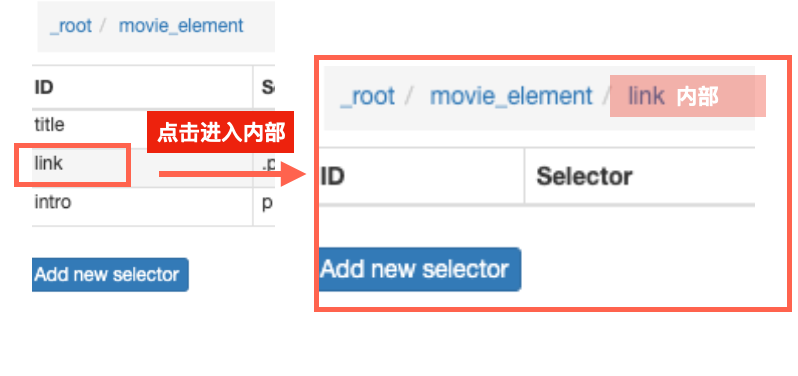
上一篇中,我们已经在“重复单元”的内部建立了针对电影名称的“selector”。
如果想要选择“重复单元”内的更多内容,只需要继续在单元内,添加新的selector即可。
比如,新建selector,选出“标题链接”部分。
比如,新建另一个selector,选出“简介”部分。
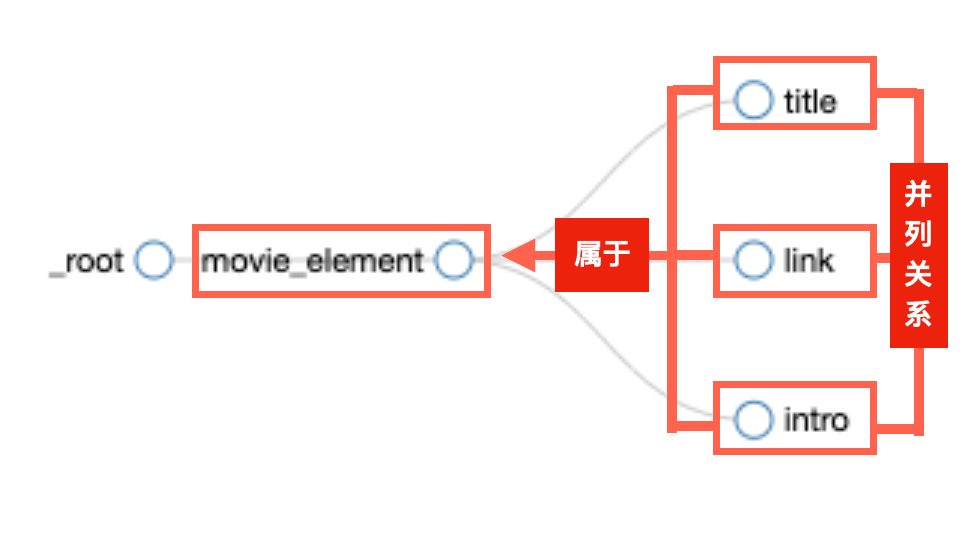
点击保存之后,能看到重返单元“movie_element”内,有三个并列的selector。
点击scrape开始爬取。
点击refresh之后,就能看见爬取的内容。
补充解释(后学)
现在我们的“网页地图”有了一定的复杂度,这里介绍一个查看“地图结构”的功能:
selector graph
点击界面第二栏的“sitemap xxx”(xxx是你设定的sitename),选择其中的“selector graph”。
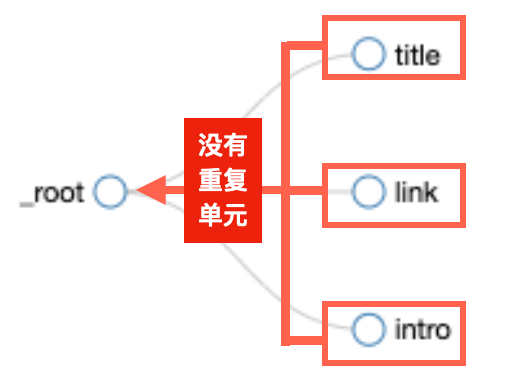
进入之后,能看到一个“root”,这相当于我们爬虫的起点,点击旁边的圆点,可以展开后续地图一点点展开。

等到把所有的圆点都点开之后,就能看到完整的“网页地图”结构了。元素之间的并列和从属关系,可以在这里看的比较明确。
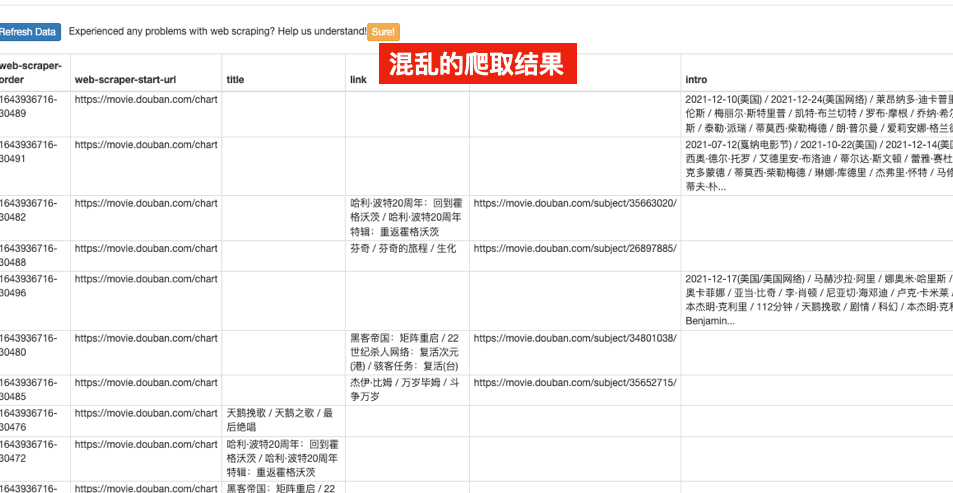
刚才的爬取结果中,每个电影的标题,简介,链接都是在同一行。
这是因为我们先选择了“电影”这个“重复单元”,然后把标题,简介,链接都“包”在了里面,所以它们才显示在了一行内。

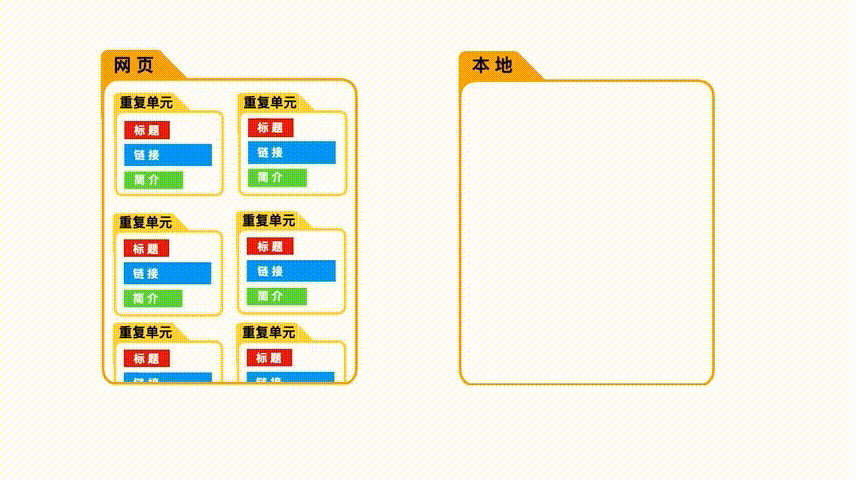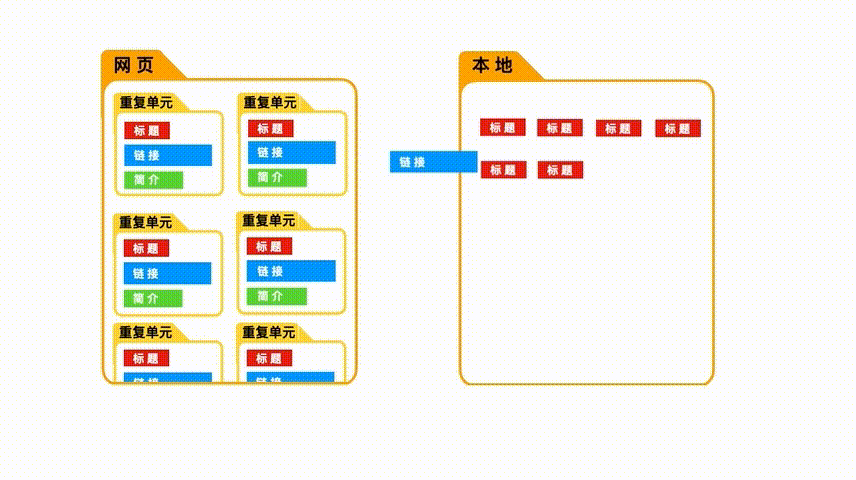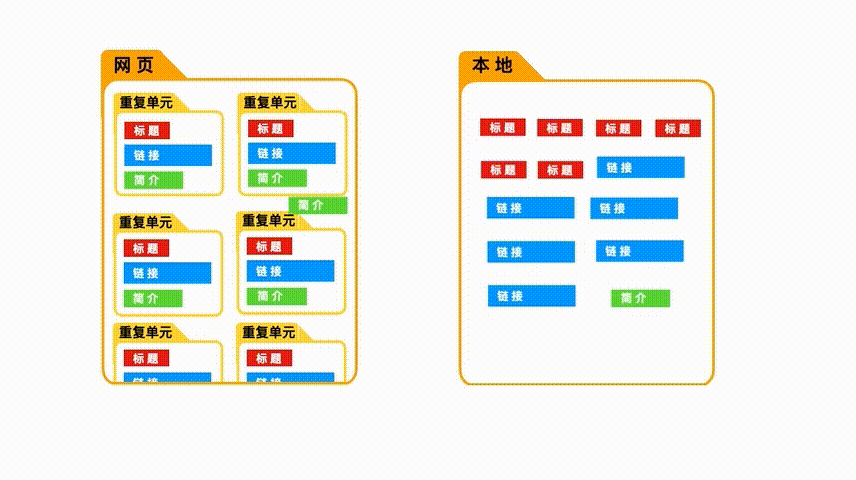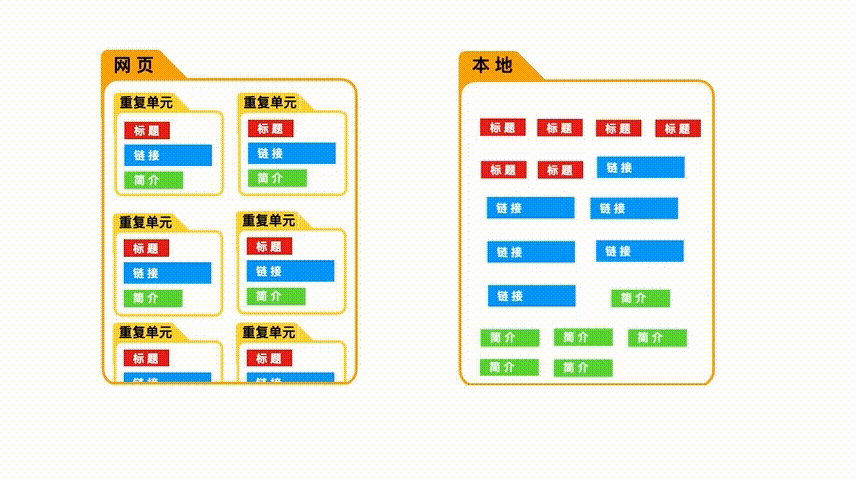
如果我们跳过了“选取重复单元”这一步,上来就直接选择标题,链接等具体数据,就会出现这样的情况。


这里用动图来解释一下:是否选取“重复单元”,爬虫的行为有什么样的变化。
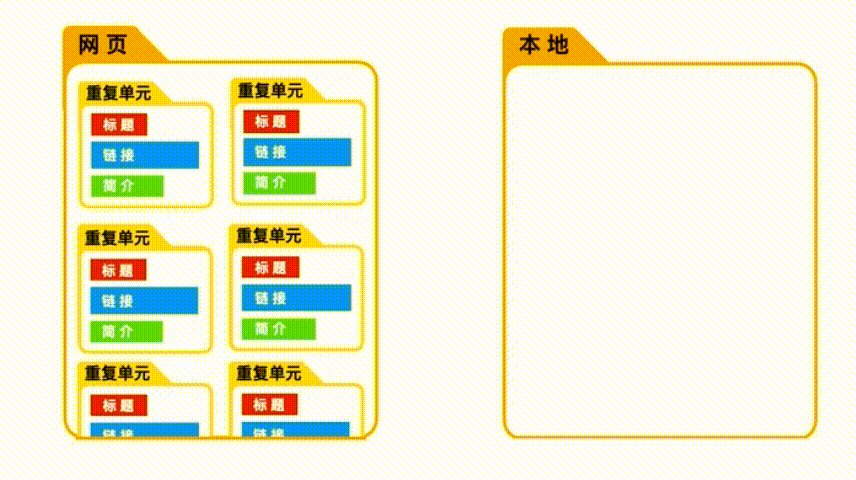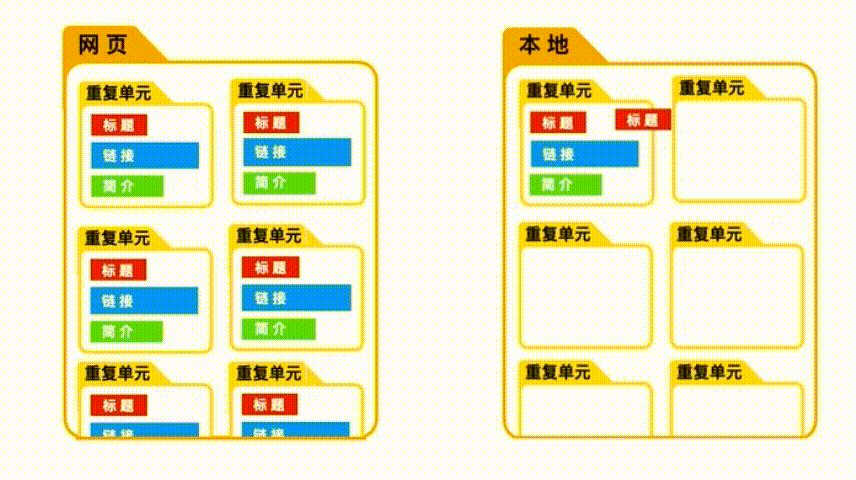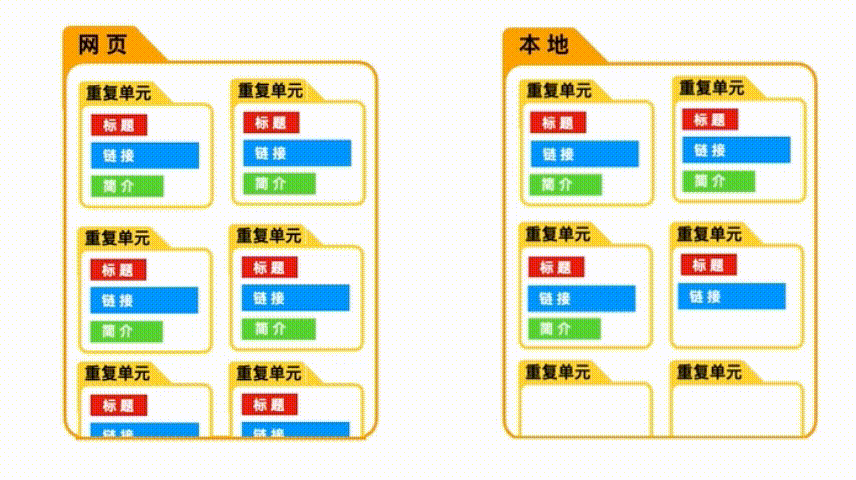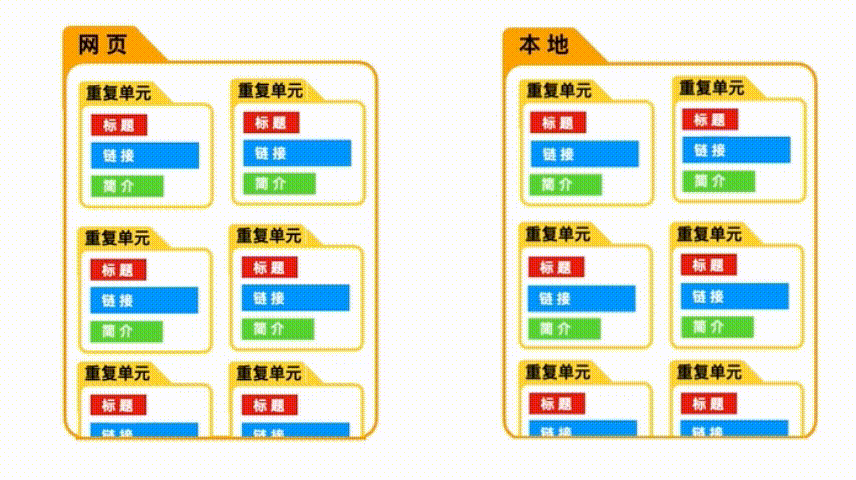
当我们选取“重复单元”时,爬虫会先把这些空的“重复单元”爬取下来, 然后再把里面的内容一个个抓取进来。

但如果我们没有选取重复单元,爬虫只会按照顺序,把选取的具体数据爬取下来,而无视他们之间的关系。

当我们只爬取一种具体数据时,是否选取“重复单元”,并不重要,因为数据间的关系很简单。
但当我们需要爬取多种数据时,如果没有“重复单元”的约束,数据之间的关系就会混乱。
我这里的建议是:
刚开始,先按照之前介绍的“三步走”方法来爬取。涉及到更深层的爬取时,可以根据实际情况,跳过“选取重复单元”这一步。
比如,进入到链接页面爬取时,推荐直接选择具体数据。
下面就来简单介绍一下。
除了“重复单元”内自带的数据外,我们还会想要爬取更深层的内容,比如某个链接页面里的内容。
这时,就可以点击进入链接的“selector”当中,进一步指定爬取规则。
下面就来介绍一下这部分的操作。
链接内爬取流程(先用)
建议大家先看一下“视频版”的演示,然后再用“图文版”进行分布操作
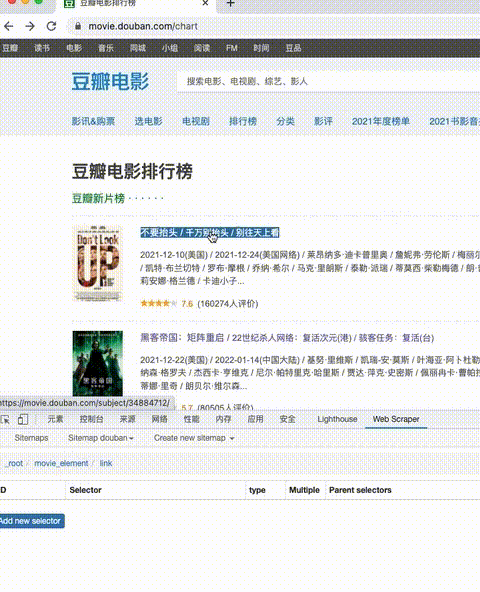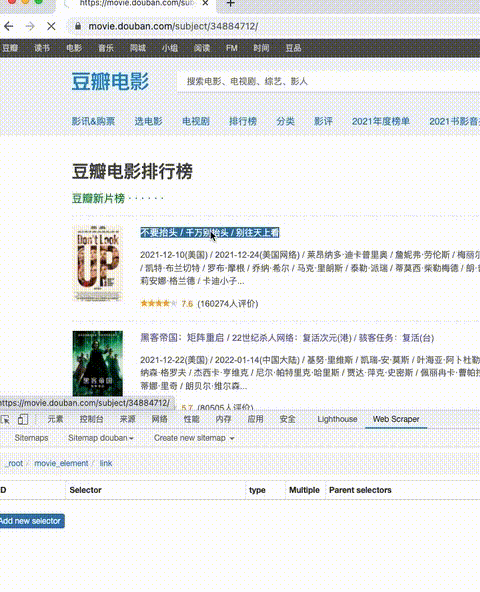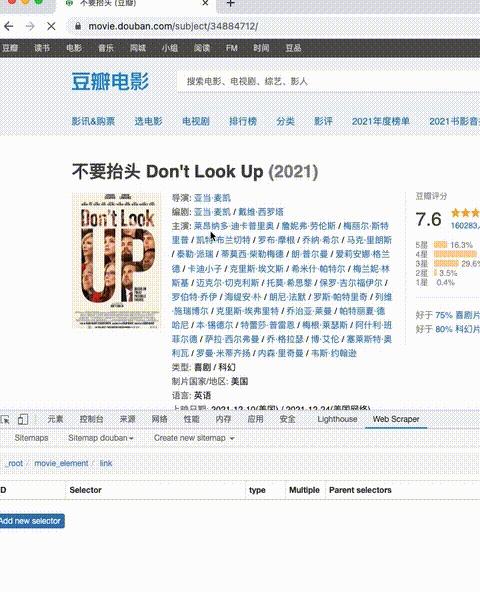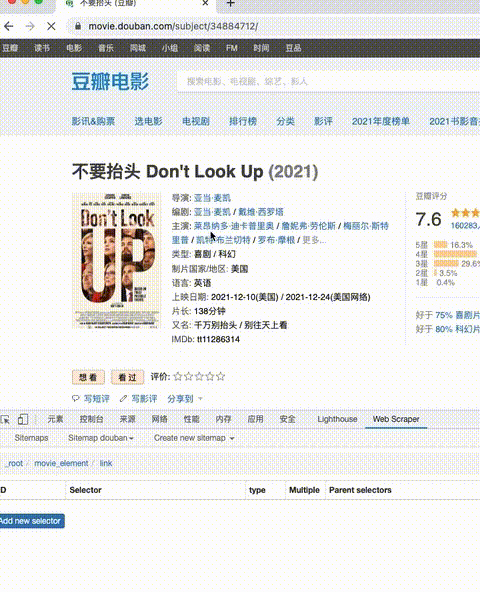
在我们刚才已经构件好的爬取规则中,有一个“链接”的selector,点击进入这个selector。

在浏览器的页面中,点击任意标题,跳转到标题链接下的页面。

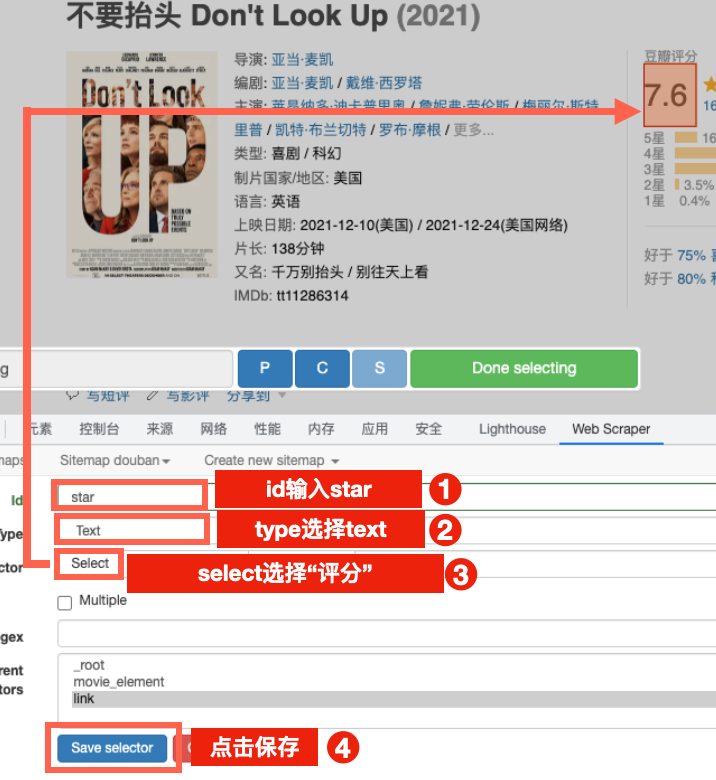
添加三个新的selector,分别爬取一下豆瓣评分,电影时长,剧情梗概。




点击scrape开始爬取,此时能看到爬虫会进入每个链接页面,进行爬取。

点击refresh之后,就能看见爬取的内容。

补充解释(后学)
当我们点击进“链接”的selector,并点开了对应的链接页面时,相当于又回到了“单页爬取”的老问题中。
我已经会解决“老问题”了,按照原来的套路来解决就好。

提示1:由于链接内的网页格式也都相同,所以点开任一链接都可以。
提示2:有些网页,如果你点击链接,它会新建一个窗口打开。
这时,可以把新建窗口的网址复制下来,然后粘贴到原窗口的地址栏,在原窗口打开链接页面,这样就不必在新窗口再次打开“开发者工具”。

作为更深一层的爬取,通常在链接页面中,我会跳过“选取重复单元”,直接爬取具体数据。
因为对于多数爬取来说,到了链接页面之后,通常不会再继续更深层的爬取了。

经过一些练习和实践之后,大家可以根据自己的工作内容,慢慢调整和修改爬取的结构。
不用害怕出错,因为大不了就重新来一次,反正又不会有什么严重后果,敢于一点点尝试,才能更好的掌握爬虫的精髓。
预告:“链接网页内部的爬取”是基础爬虫的纵向拓展,“多个页面的爬取”就属于横向拓展了。
下一篇,我们来讲一下多个页面(翻页/下拉/加载)的爬取。
把爬虫的“横纵拓展”搞定之后,就相当于搞定了几乎所有的爬虫技巧,并且可以应对工作中的绝大部分场景了
推荐文章: