有了上节课的基础,单个页面内的内容爬取,基本上我们都掌握了,剩下的就是搞定多个页面的爬取.
下面依次介绍一下:翻页爬取,加载爬取,下拉爬取。
前几篇关于基础步骤的介绍已经比较详细了,所以这里不多解释,只把各个步骤的设置截图放出来。
如果有不清楚的读者,建议还是按照之前的顺序,先看完视频演示,然后再根据图文教程来完成操作。
翻页爬取
目标网页:李永乐老师的B站主页。
目标内容:每个视频的标题,链接,观看数。
1.创建网页地图
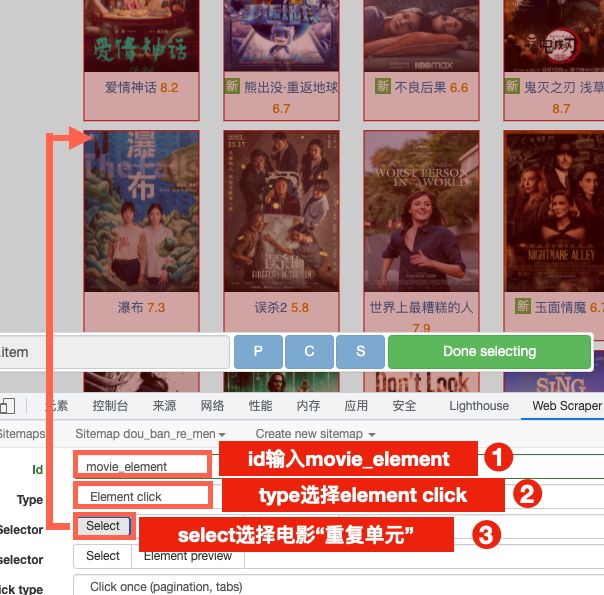
2.选取重复单元
注意:此时的type要用到element click这个选项。
这个页面和原来element相同的地方,我们按照原来的方式,把基础的重复单元都选取出来即可。
提示:可以先选中所有的视频标题,然后用“P”键顺藤摸瓜,找出所有“重复单元”
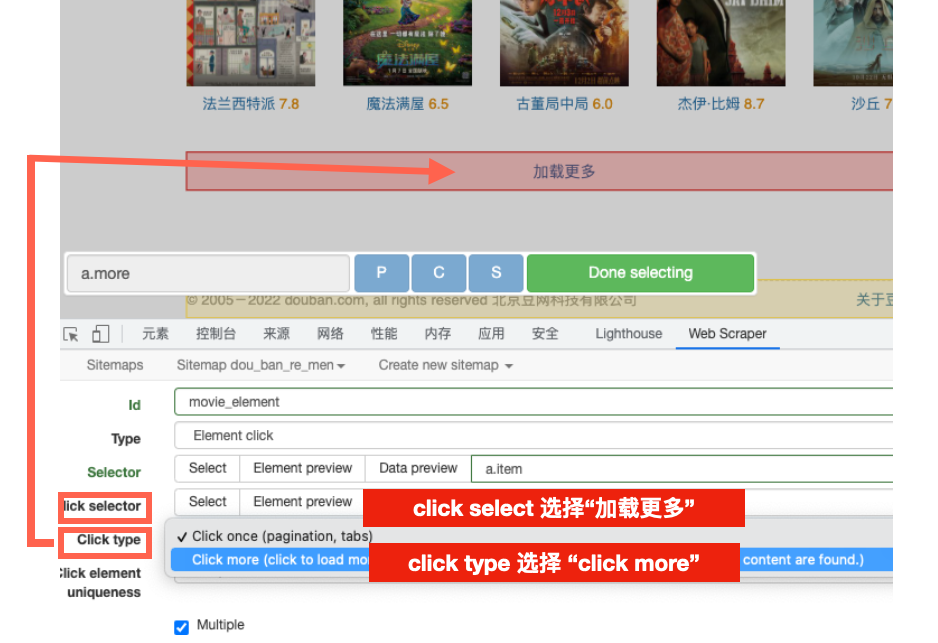
多出来的选项,就是用来点击“下一页”的,按照如下方法选取即可。
点击 click selector 当中 select,然后将鼠标移动到“下一页”,点击选取。
click type 选择click more,最后点击保存。

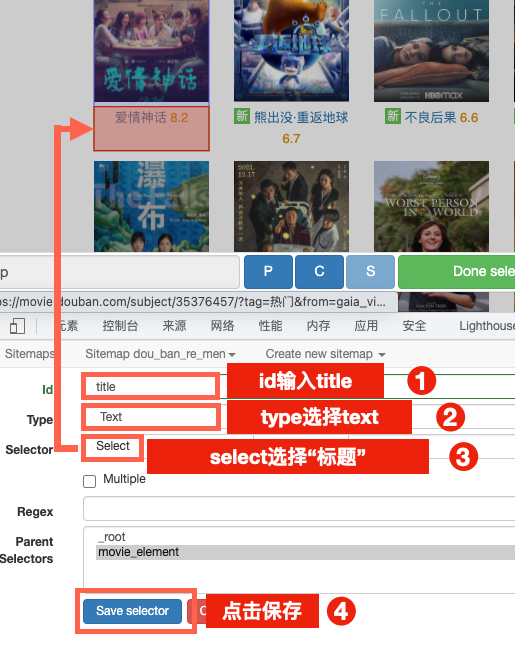
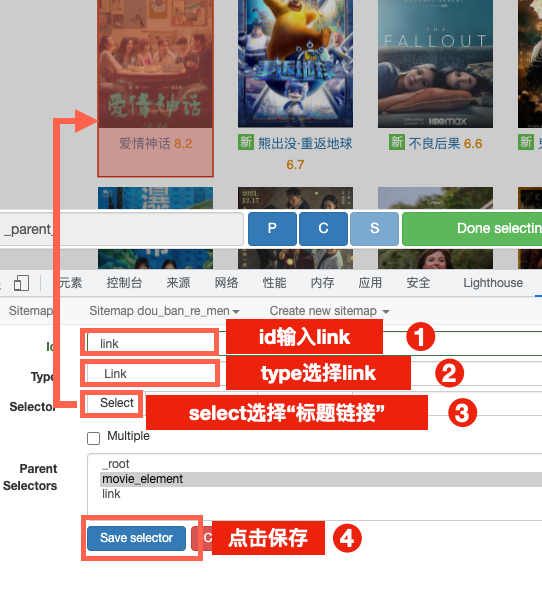
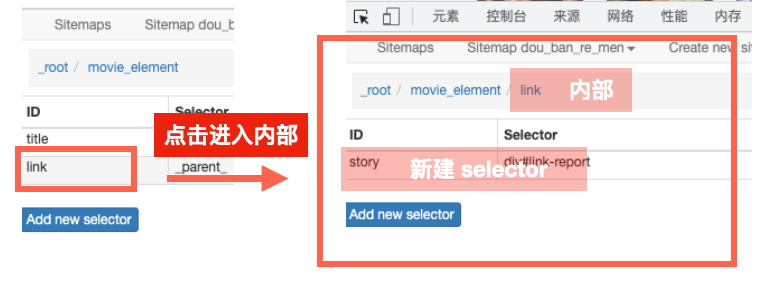
3.选取单元内数据
点击进入到重复单元的内部,创建具体数据的爬取规则。
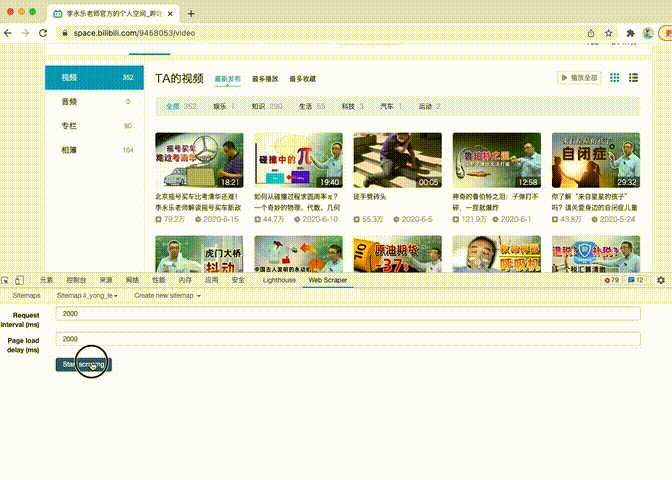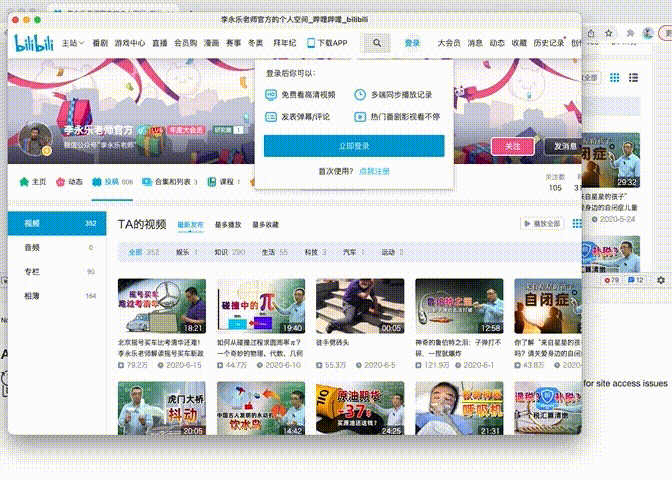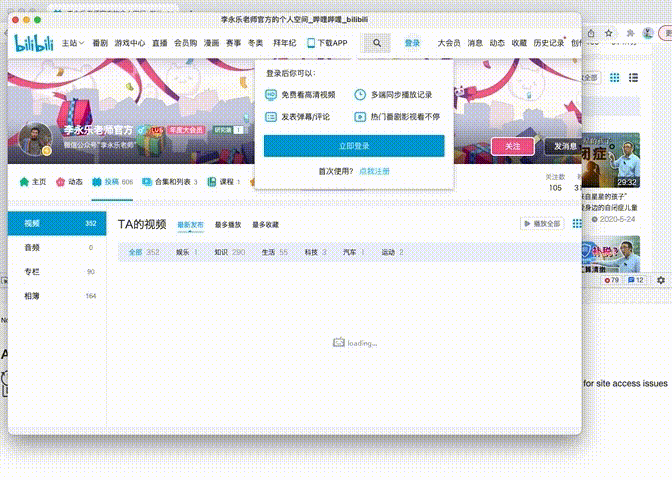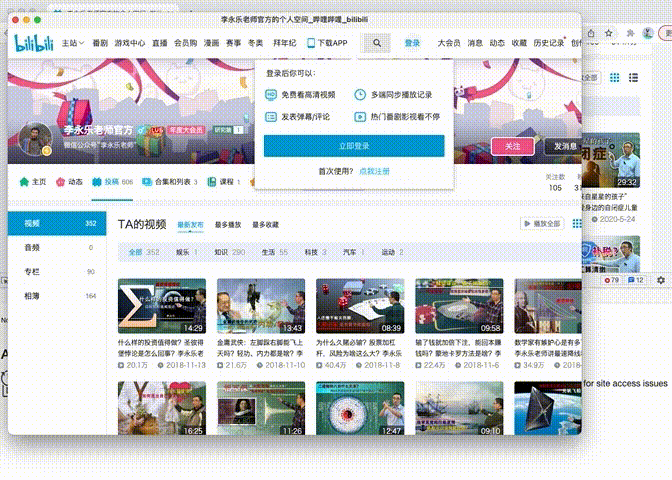
创建完成之后,开始爬取,会看到页面在不断翻页爬取。
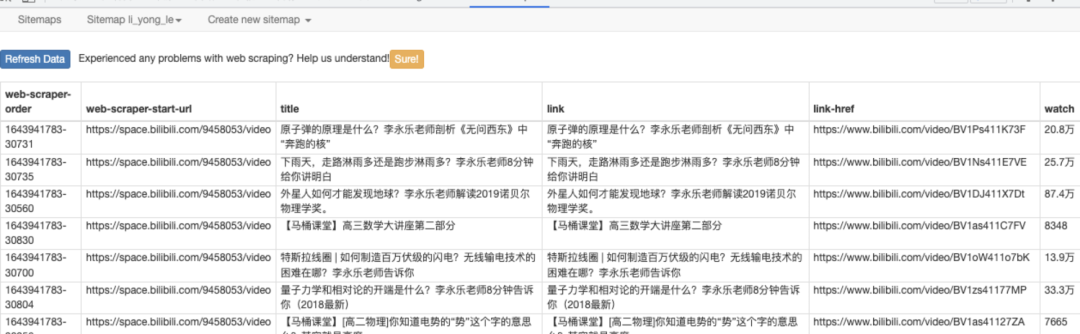
爬取完成后,点击刷新,看到爬取结果。
加载爬取
目标网页:豆瓣热门电影
目标内容:电影标题,电影链接,剧情简介。
1.创建网页地图

2.选取重复单元
此时的type还是用element click这个选项,重复单元的选择如图
提示:可以先选中所有的电影图片,然后用“P”键顺藤摸瓜,找出所有“重复单元”

click selector 这次选择“加载更多”,click type 选择click more,点击保存。

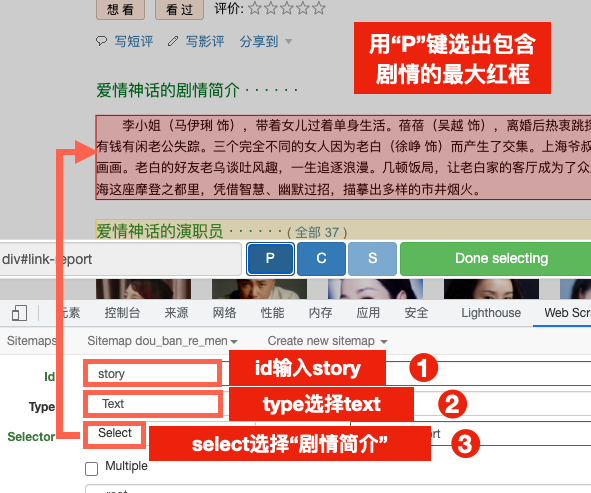
3.选取单元内数据
点击进入到重复单元的内部,创建具体数据的爬取规则。



进入链接内部,并点开任一电影链接页面。


创建完成之后,点击爬取,会看到页面在不断加载爬取。
由于爬取的内容较多,可能会触发网站的反爬机制,建议大家在爬取时,将时间间隔设置大一些(5000~10000)

爬取完成后,点击刷新,看到爬取结果。

下拉爬取
目标网页:抖音主播(机器人十七)主页
目标内容:视频链接,点赞数
1.创建网页地图

2.选取重复单元
此时的type选取element scroll down 这个选项,其余选择和选取“重复单元”时相同。
提示:顺藤摸瓜寻找“重复单元”时,尽量选择最大的框,否则有些单元内的内容(比如链接)可能会遗漏。

3.选取单元内数据
点击进入到重复单元的内部,创建具体数据的爬取规则。



创建完成之后,开始爬取,会看到页面在不断下拉。

爬取完成后,点击刷新,看到爬取结果。

解释部分
跟着上述的三个流程做完一遍的朋友,现在可能已经有些体会了。
不论是翻页,加载,还是下拉,其实目的只有一个:
把所有“重复单元”先都找出来
所以我们就用了 element click(点击) 和 element scroll down(下拉)这两个类型。
在选取重复单元的同时,让网页自动点击“下一页/加载”或自动“下拉”,直到把所有的重复单元都找出来,然后再一个个爬取内部数据。
只要理解了这一步,基本上多页的爬取也就掌握了。
总结
到目前为止,我们的教程已经覆盖了大部分基础需求。
掌握了这几节的内容,如果你在工作生活中需要爬取网上内容,基本上不会有太大的问题。
但总会有一些“漏网之鱼”,是我们的教程没有覆盖到的,所以在后面的教程中,我会挑一些我遇到的“犄角旮旯”的问题,以及相应的解决方法。
如果大家在使用这个教程中,遇到了任何问题,也欢迎通过留言来交流。
推荐文章: