上一篇我们安装好了Web Scraper,并且快速体验了一把爬虫的感觉。
之所以按照这个流程,先给大家“剧透”些结果,是因为我这些年总结的一个规律。
一个优质的教程通常是:
先用后学
用最简单的步骤,让学生先把流程跑通,获得一些成就感之后,再回过头来解释其中的关键步骤。
学生在使用过程中,自己会体会到一些东西。在这个基础上,再给出一些提示,基本就能掌握这个技能了。
所以后面的教程都会按照“实用流程(先用)+补充解释(后学)”的顺序来安排。
闲话不多说,我们先来爬取一个网页。
提示1:对于没有看过上篇的朋友,建议大家先去看一下基础的介绍,然后在后台回复“爬虫”,来提取教程中所需的相关文件。
上一篇链接:【教程】我学会它之后,逃离了内卷,收入也翻倍了
提示2:如果有条件,建议大家用一个屏幕看教程(ipad,手机,另一个笔记本电脑),然后在电脑上操作,这样来回切换的成本比较小。
使用流程(先用)
建议大家先看一下“视频版”的演示,然后再用“图文版”进行分布操作。
作为开始的例子,我们先来爬取一个简单的网页:豆瓣电影排行榜。
提示1:教程中会用到的网站地址,我已经单独整理好,放在了网盘文件夹当中,大家不必再重新搜索,直接复制粘贴到地址栏即可(后台回复“爬虫”即可提取)。
提示2:读者阅读教程时,某些网站的内容可能有些变化(比如电影排行榜中的电影),但不影响教程的使用,大家依旧可以按照教程操作。
提示3:由于是小白教程,所以我会详细拆解每个步骤,等到后期熟练之后,只需要花1~2分钟,即可完成爬虫的设置。
打开浏览器,在地址栏粘贴上“豆瓣电影排行榜”的网址,打开网页(也可以自己百度一下,找到这个对应的页面)
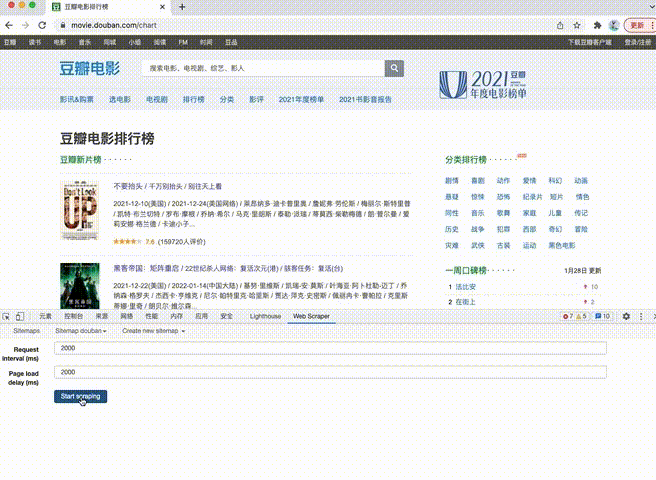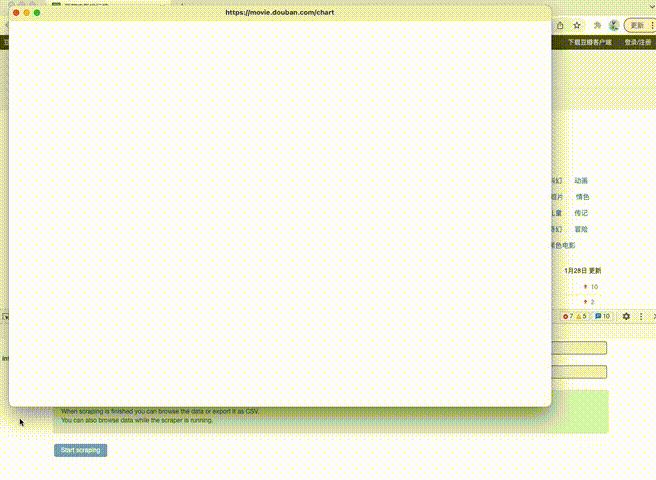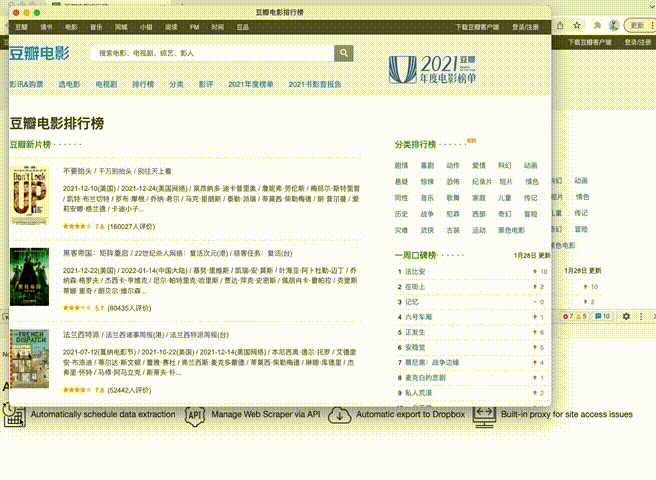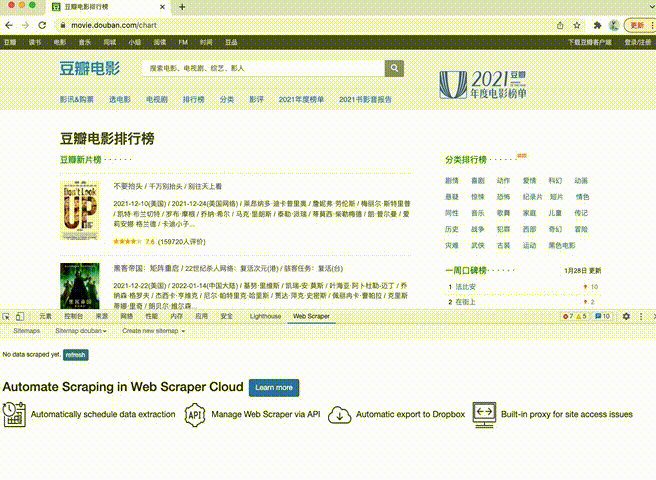
在网页任意位置,点击右键,选择“检查”,打开“开发者工具”窗口。
随后,点击“Web Scraper”进入爬虫的操作界面。
点击界面上方第三栏“Create new sitemap”,在下拉菜单中选择“Create Sitemap”.
“Sitemap name”一栏输入douban,“Start URL”一栏复制粘贴进“豆瓣电影排行榜”的网址,点击“Create Sitemap”
提示:如果在上一篇,你已经用了“douban”这个名称的网页地图,可以换一个名字,比如“dou_ban_dian_ying”
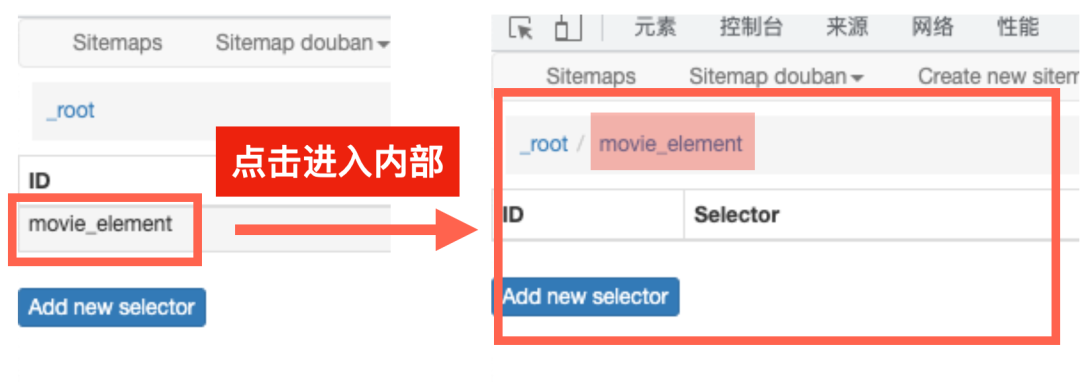
现在我们已经进入到了刚刚创建的“douban” 网页地图的根目录中,这一点可以从界面的第二栏的名称和左侧的“root”看出。
下面要创建爬取规则,点击“Add new selector”,进入爬取规则创建页面。
“id”一栏输入movie_element,“type”一栏点击下拉框,选择“element”。
“selector”一栏点击select。此时,电影排行榜的页面会变暗,然后在开发者工具窗口上方会弹出一个小对话框。
将鼠标移动到页面上,会看到鼠标停留的位置会识别出黄色的框。
鼠标移动到第一个电影的标题处,然后单击选中,黄色的框会变红,表明已经选中。
然后用同样的方法,选中第二个标题。

点击第二个标题的同时,会发现下方所有的标题都被自动识别了出来。

在刚才弹出的小对话框中,有三个蓝色的按钮(P/C/S)一个绿色按钮(Done selecting)。
点击其中的“P”键,会看到原来只选中标题的红框,会一点点扩大范围,包含进了更多东西。
连续点击几下(大约3~4下),直到每个红色的框,把对应电影的信息全都“框进来”为止(如果点击太快,点过头了,可以点击C键返回上一步)
确保每个框把对应的电影信息都包含之后,点击绿色按钮(Done selecting)。

确认“multiple”选项处于勾选状态。

其余选项不用动,点击“Save selector”保存设置。这样我们就建立了名为“movie_element”的选择器。

这是最核心的一步,我们相当于把每个电影都选中了。
后面想提取每个电影的任何信息,只需要点击进入刚才建立好的名为“movie_element”的选择器当中,就可以获取了。
比如,我们来爬取一下每个电影的标题。
点击进入“movie_element” 选择器当中。

点击“Add new selector”,进入爬取规则创建页面。
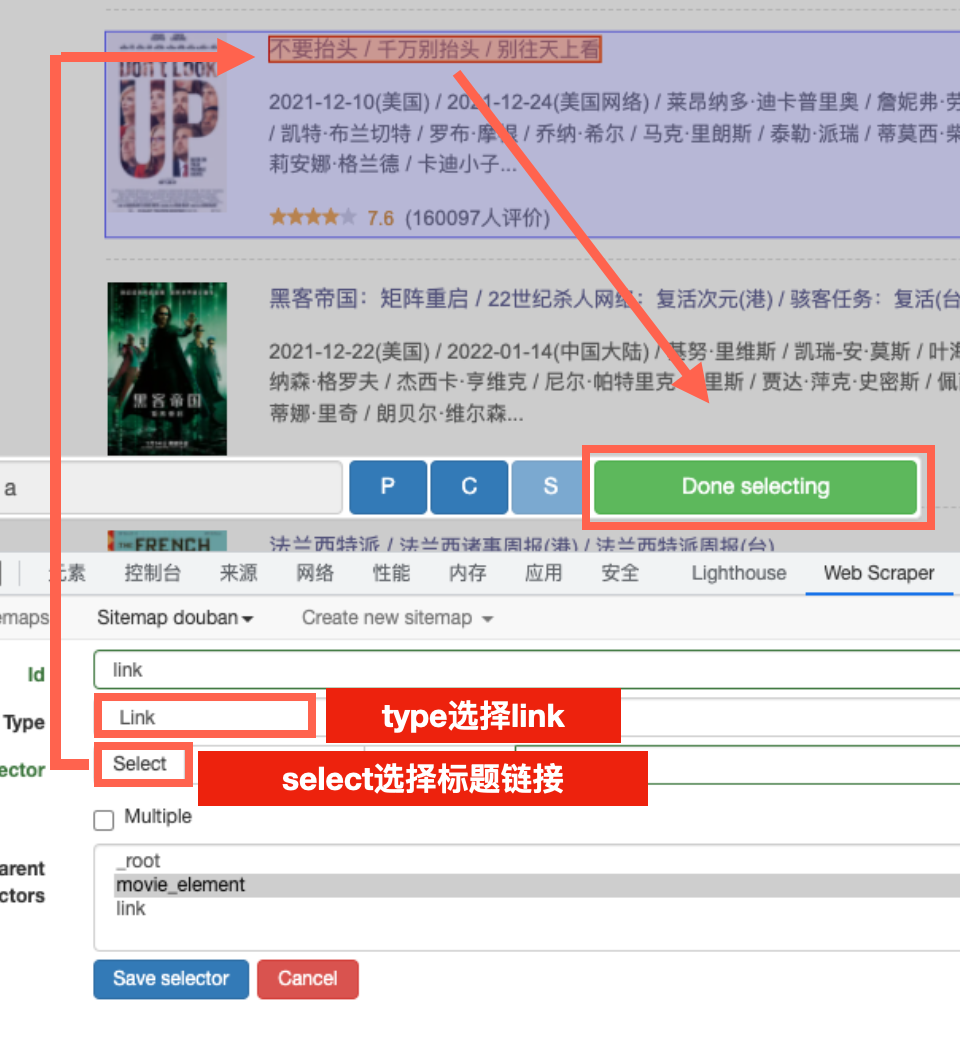
“id”一栏输入“title”,“type”一栏不动,就选择现在的“Text”。
在“selector”一栏,点击“select”,此时小对话框弹出,页面出现一个蓝色的框,也就是我们在上一步选中的movie_element,但是只有第一个电影有,其他部分依然是灰色的。
将鼠标移动到蓝框当中,点击选择标题,然后点击小对话框中的“Done selecting”,保存选择。
其余部分不动,点击“Save selector”,保存设置。

这样我们就编辑好了爬取标题的选择器,下面开始爬取。
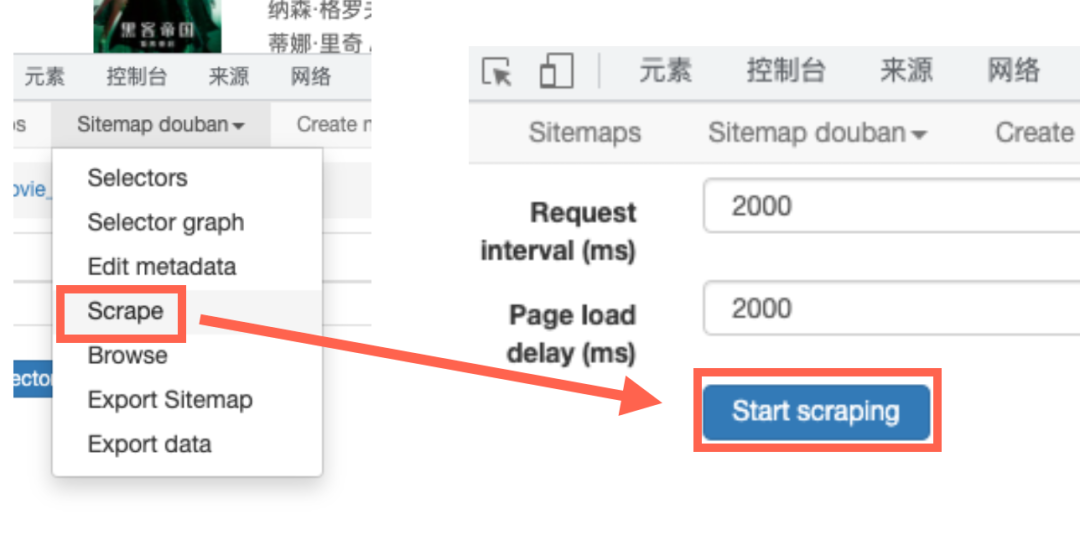
点击菜单栏的第二项,在下拉菜单中选择“Scrape”。
弹出界面中的“Request interval (ms)”和“Page load delay (ms)”用默认值,直接点击下方的“Start Scraping”。

随后可以看到自动弹出了一个浏览器窗口,显示的正是我们“排行榜”的页面,这就是电脑在自动爬取的标志。

由于我们需要爬取的数据很小,这个窗口大概持续2~3秒就会自动关闭。
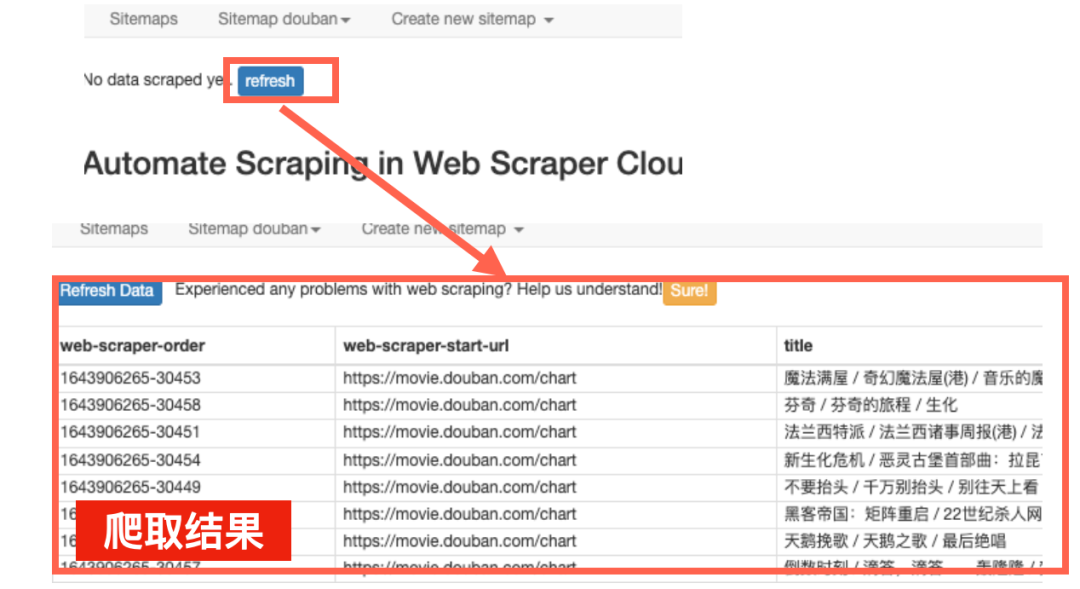
然后Web Scraper会自动跳转到结果的查看页。点击其中的“refresh”刷新一下,可以看到刚才电脑爬取的内容。
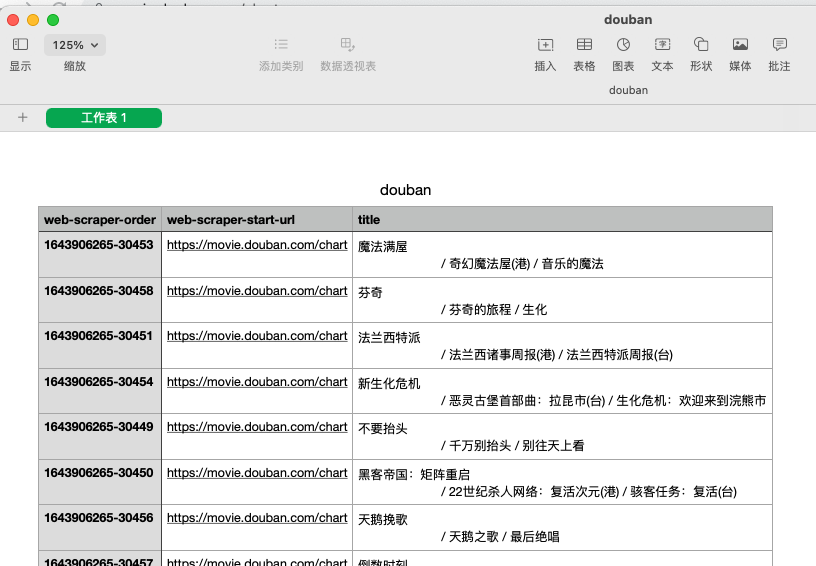
每个电影的标题,都被存放在了“title”这一列当中。
提示:刷新的爬取结果顺序可能和原网页不同,但只要将结果下载下来,按照第一列的“web-scraper-order”进行排序,就能恢复原来的网页顺序。

点击菜单栏第二项,在下拉菜单中选择“Export data”,可以将爬取内容下载下来。
下载的格式有两种,分别是:xlsx(excel软件格式), csv(编程常用的表格格式)
点击对应按钮,下载文件。

打开文件,就能看到我们刚才爬取的内容了。

以上是一次简单的单页面爬取的详细流程。
跟着步骤操作的过程中,大家可能多少也对Web Scraper大体的操作逻辑有了些概念,下面我们针对其中的一些环节,进行简单的补充解释。
了解完这部分基础逻辑之后,后面再去学习复杂一点的页面爬取就会比较容易了。
补充解释(后学)
下面简单解释下,我们刚才那些设置,到底再给Web Scraper下达什么样的指令。
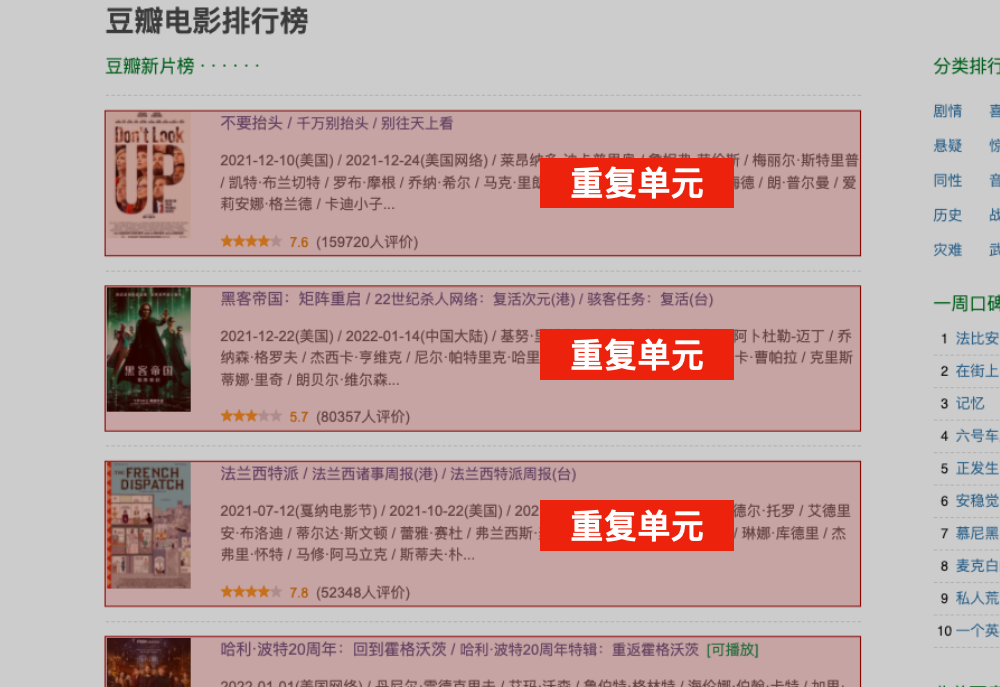
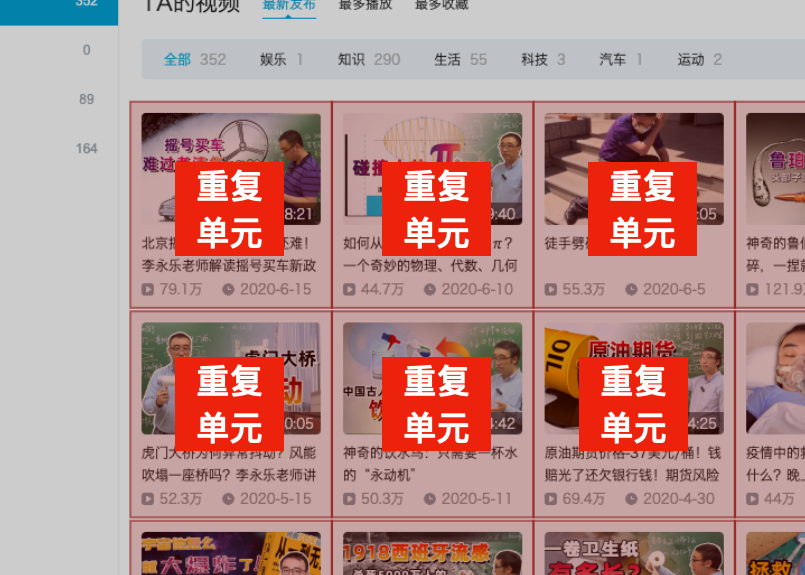
我们可以把网页中的条目,看成是一个个的文件夹,文件夹里含有具体信息。
而这种文件夹通常会有规律地重复出现,我们可以称它为:
重复单元
举几个例子,马上就能知道,这种“重复单元”长什么样了。



我们想要爬取的信息,通常都包含在这些“重复单元”里,并且都是相同格式,在相同位置。

所以我们可以先把所有“重复单元”都选出来,然后选其中的一个作为代表,告诉电脑要爬取里面的哪个数据。
然后,电脑就会按照这个规则,把所有“重复单元”对应位置的数据都爬取下来了。
虽然上面做了很多操作,但总结起来,大的逻辑框架就三步:
1.确定目标网站,新建一个“网页地图”2.根据想爬取的内容,选出所有“重复单元”3.在单元内选择具体数据,实现批量爬取
1.创建网页地图
这是主界面第三栏“create new sitemap”的作用。
相当于给爬虫指定一个起点,告诉它从哪里开始爬取数据,所以叫网页地图(sitemap)

其中的“site name”可以任意设置,但为了后期查找方便,通常根据网站和爬取内容来设置。
所有创建好的“网页地图”都会被保存起来,方便重复使用。

注意:
不管是这里的“site name”还是后面的“id”,涉及到起名的地方,都需要遵守以下格式。
只能使用小写字母,数字和一些基础符号(,_+-),而且长度不能小于三个字母。
起名时一方面保证自己看得懂,另一方面也避免和已有地图重名的情况。
2.选取重复单元
创建好网页地图之后,会自动跳转到地图之内。
这里的selector是选择器,我们通过建立selector,来给爬虫下达的指令,告诉它我们想要爬取什么。

简单介绍下选择器内部的选项。
id:选择器的名称
根据爬取内容来起,方便自己看懂(和sitename一样)
type:指定数据类型
最常用的有三种 text/link 和 element,其余的image, table等类型,大家可以在熟练之后,自己慢慢探索。
text用来选取文本,link用来选取链接,都是具体的数据。
element用来选取“重复单元”,并不是具体数据。

selector:定位爬取位置
指定完数据类型,得告诉电脑这些内容在网页的什么地方,所以需要用“select”键来定位。
比如,我们想把所有电影,作为“重复单元”选出来。
设定好id和type之后,用select选出每个“电影”

但有时候,直接选出“重复单元”有点难。这时,我们可以用弹出的小对话框,顺藤摸瓜地间接选出“重复单元”。
就像之前的流程里操作的一样,先选出所有的标题(不要只选一个),然后点击小对话框里的“P”键(Parent),一点点找到上级的元素。

注意1:当你连续选取了两种同类元素时,电脑会自动识别出后续所有同类元素,并且一起帮你选中。
注意2:识别的顺序是从上到下。如果想选中所有目标元素,要从第一个条目开始选择,否则上方的未选择部分,不会被电脑识别出来。

注意3:建议大家在选取网页条目时,多使用下“P”和“C”键的顺藤摸瓜方法,选出一个包含目标条目的最大红框,以保证后期爬取不会遗漏内容。
比如,如果我想选择这部分文字,我会通过点击“P”和“C”键,找到最大的红框。

multiple:多选
虽然select会自动识别所有同类元素,但如果没有勾选“multiple”选项,爬虫只会爬取刚才选取的第一项。
这四个选项设置好之后,点击保存,就完成了对于“重复单元”的选取。
3.选取单元内数据
选取完“重复单元”之后,点击进入“单元内”,进行具体数据爬取规则的创建。

新建一个选择器,界面和上述相同。
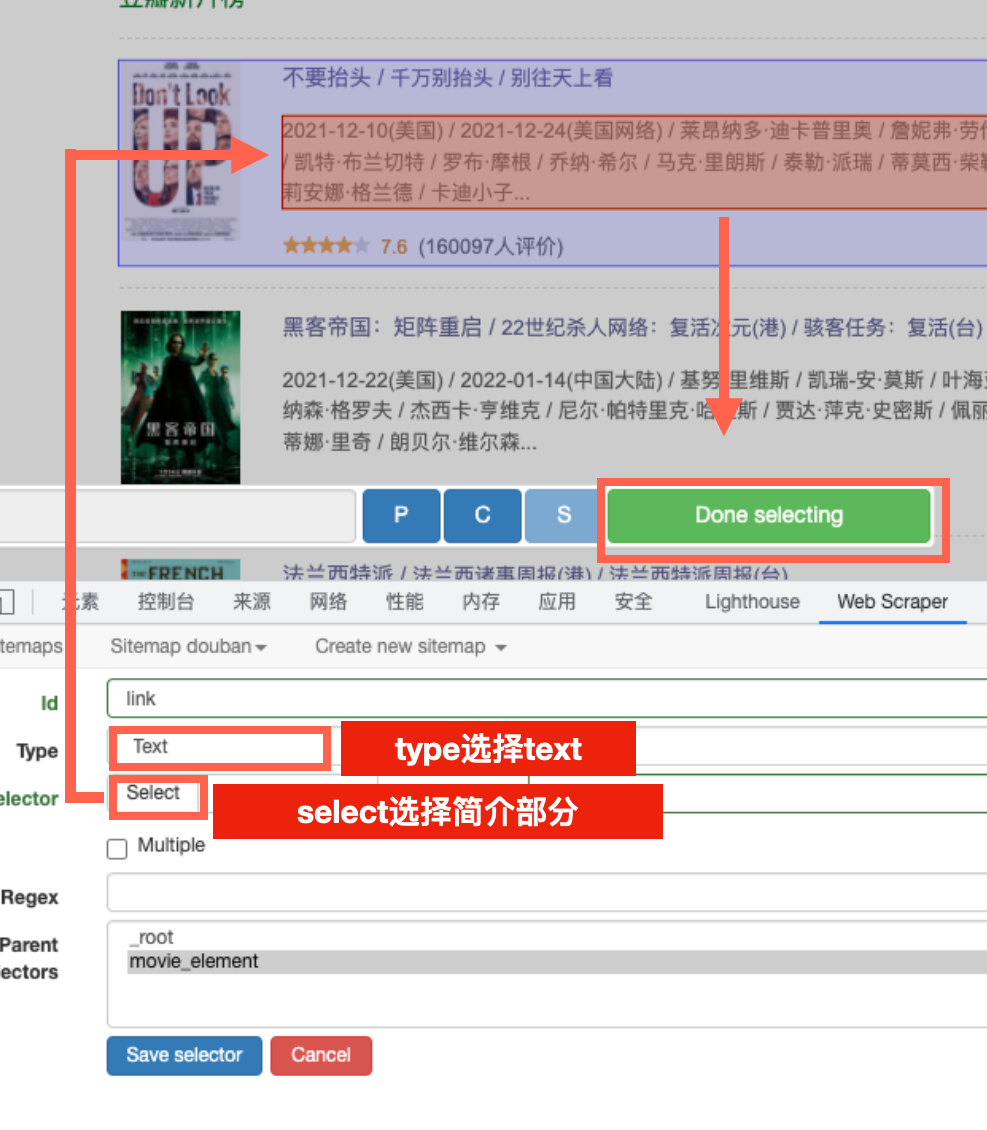
此次针对的不是“重复单元”,而是“具体数据”,所以type就不选择“element”了。想要爬取文字,就选“text”,想爬取链接,就选“link”。
点击select,网页中只会出现“一个”蓝框,作为所有“重复单元”的代表。
只要选中蓝框中的某个数据,爬虫会自动把所有“重复单元”的这类数据都选取出来。
比如,我们要爬取每个电影的标题链接,可以如下设定和选择

如果要爬取每个电影的简介,可以如下设定和选择。

以上三步完成以后,对于爬虫的设定就算完成了。
随后可以点击主界面第二栏的“Sitemap xxx”,点击其中的scrape进行爬取。
其中的两个数值是执行的时间,如果网速比较慢,或者担心触发网站的反爬机制,可以适当设置为更大的数字。

爬取后可以点击“refresh”来查看结果,然后用“export data”来下载数据文件。
这篇教程把基础流程和大体逻辑讲了一下。
由于是基础内容,所以我尽量详尽地介绍了每个步骤和背后的原理。
练习过几次,熟练之后,基本上1~2分钟就能搞定。后期的教程,我也会慢慢简化设定,专注于未讲解过的部分。
更复杂的爬取过程,其实也只是基础步骤的拓展而已,不会有太大的变化。
预告:下一篇我们来讲解一下如何爬取多个数据,以及如何进入链接爬取更多内容。
推荐文章: