之前在新东方教书,收入和带的学生量成正比。带的学生越多,课时费就越多。
但问题是,学生多,每天要处理的信息也多,同时还得准备大量备考材料,所以老师带的学生量是有天花板的。
虽然那时候“内卷”这个词儿还没火,但我已经感觉整个人在被慢慢掏空。
每天做的都是重复性劳动,纯粹用时间换金钱。
为了防止情况恶化,我就硬着头皮学了些编程技巧,让电脑帮我分担了这部分体力活儿。
比如,在备考网站上,把需要的材料都复制粘贴下来(爬虫)

比如,根据学生做的阅读题,自动生成生词表,来督促他复习(python)
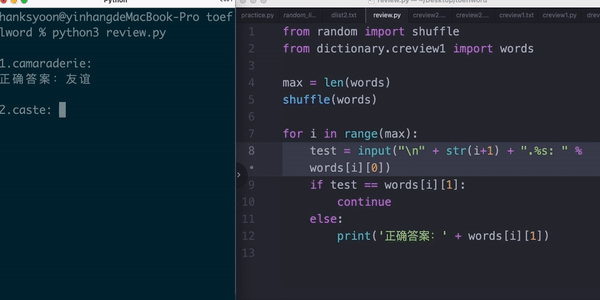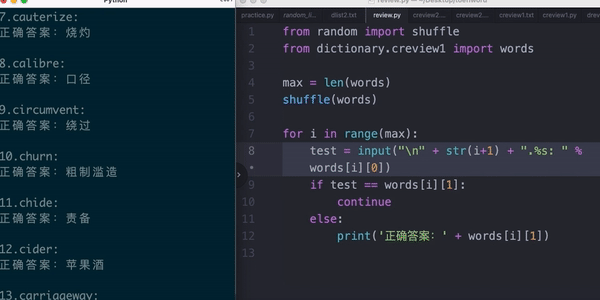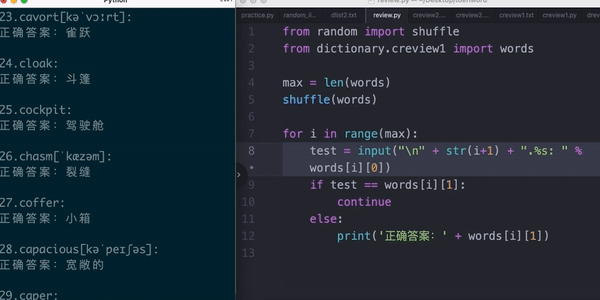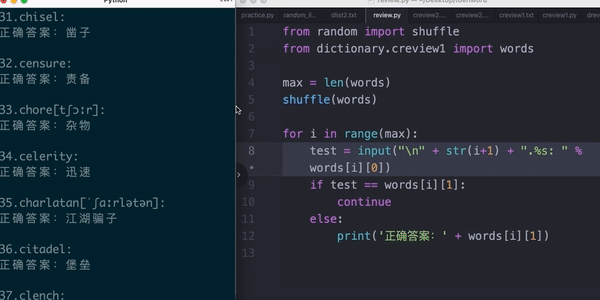
比如,把听力音频逐句切割,发给学生练习听力(ffmpeg)

等我利用编程和各种工具,把一半的工作分给电脑后,发现自己能带的学生,比其他老师多了3~5倍,原来的天花板被我给掀翻了。
更重要的发现是:
编程这东西没多难。
主要是市面上的教程都太理论化。总是冲着“大而全”来设计,目标是把你培养成一个程序员。
可我没必要成为一个程序员啊!我就想解决点工作中的小问题啊!
我只想让电脑帮我做点体力活儿,减轻我的工作压力,让我多点空闲时间,这个要求不高啊!
我想多数人和我的想法是一样的。
比如,前段时间和一个朋友聊天,他从事证券行业,需要在网上批量搜集公司信息。上百家公司的内容,需要一次次复制粘贴,效率实在太低。
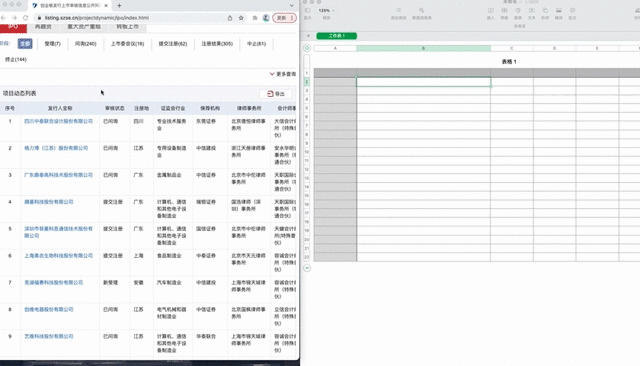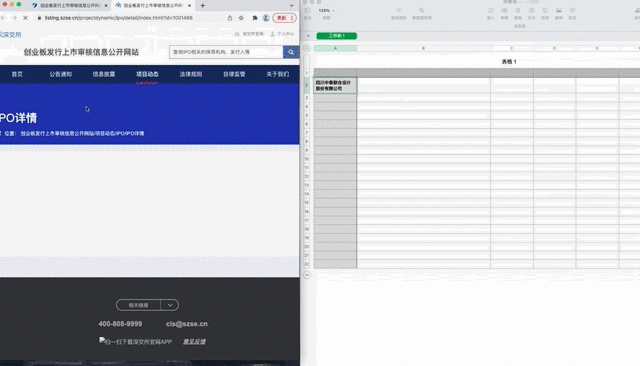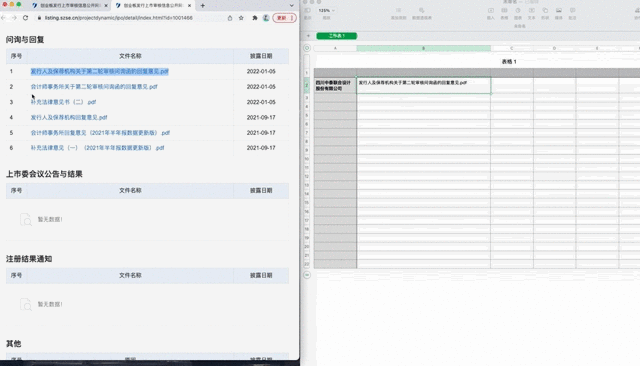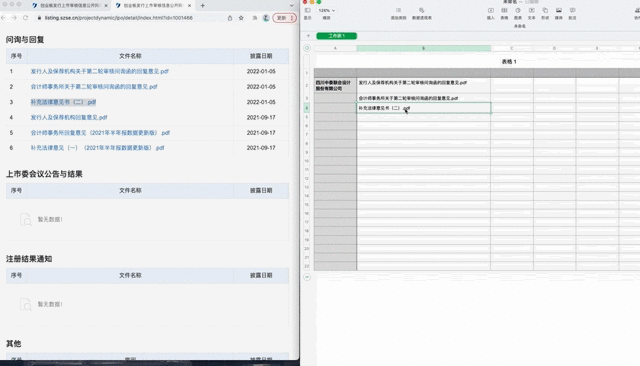
了解了他的需求之后,我用之前学的爬虫工具,十分钟帮他搞定了一天的工作。

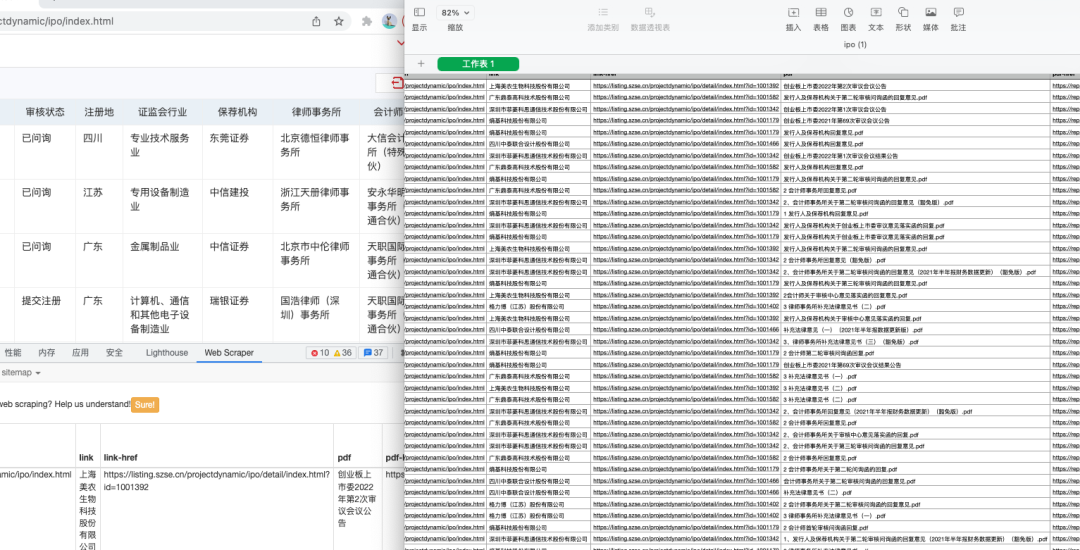
关键是,掌握这个工具,并不需要你报几千块的课,花几个月时间。只要你有电脑,愿意抽出1~2个小时就行。
想到很多读者和我这位朋友一样,被重复性工作绑架,宝贵的时间和精力都被浪费了,我就觉得应该好好写一套系列教程,把我之前如何逃离“内卷”,提升效率的经验总结下。
第一个给大家介绍的,就是这个爬取工具:
Web Scraper
利用这个工具,可以实现绝大部分网页的爬取,关键在于:
不需要编程基础
所以大家不必担心学不会,只要跟着后面的教程一步步操作,基本上都可以掌握。
这个过程中,你能感觉掌握一个高级工具之后,自己的工作生活能有多大的质量提升。
课前准备
Web Scraper 是一个浏览器插件,目前支持谷歌浏览器和火狐浏览器。
因为一些朋友无法访问谷歌,所以我将所需的文件资源都存放到了网盘中,大家在公众号后台回复关键词“爬虫”,就可以看到提取的链接。
不论你是否能访问谷歌,都建议你采用这个方式来安装。
因为这是我验证过的一个版本,后面的教程也都会依照此版本进行。
打开网盘链接后,根据自己的电脑系统(Windows/苹果),选择对应的文件夹下载。
下载完成之后,首先安装浏览器(谷歌/火狐)
Windows用户推荐安装火狐浏览器,苹果用户推荐安装谷歌浏览器。
(如果电脑中已有某款浏览器,可以跳过这部分,直接看插件的安装步骤)
安装过程和其他软件相同,双击打开软件,按照导引操作即可。
 (Windows,火狐浏览器,双击后安装)
(Windows,火狐浏览器,双击后安装)
 (苹果系统,谷歌浏览器,双击后拖动到应用文件夹)
(苹果系统,谷歌浏览器,双击后拖动到应用文件夹)
下面介绍下,浏览器中插件的安装,以及爬虫的初体验。
火狐浏览器
安装好浏览器之后,打开浏览器,选择右上角的“三杠”,点击“更多工具”,然后选择“面向开发者的扩展”。
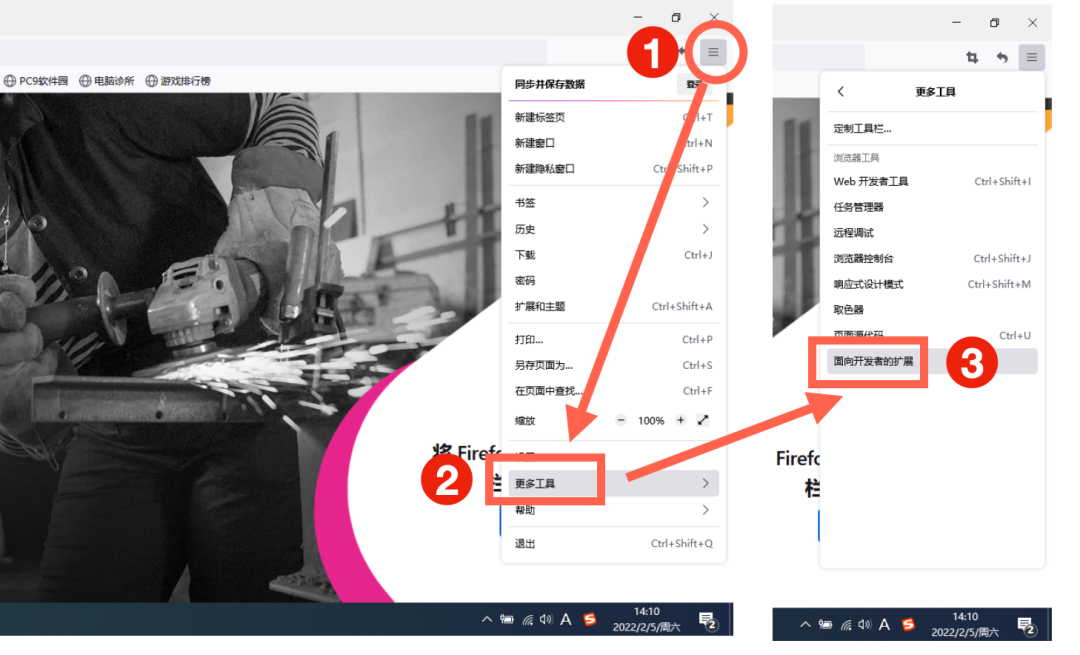
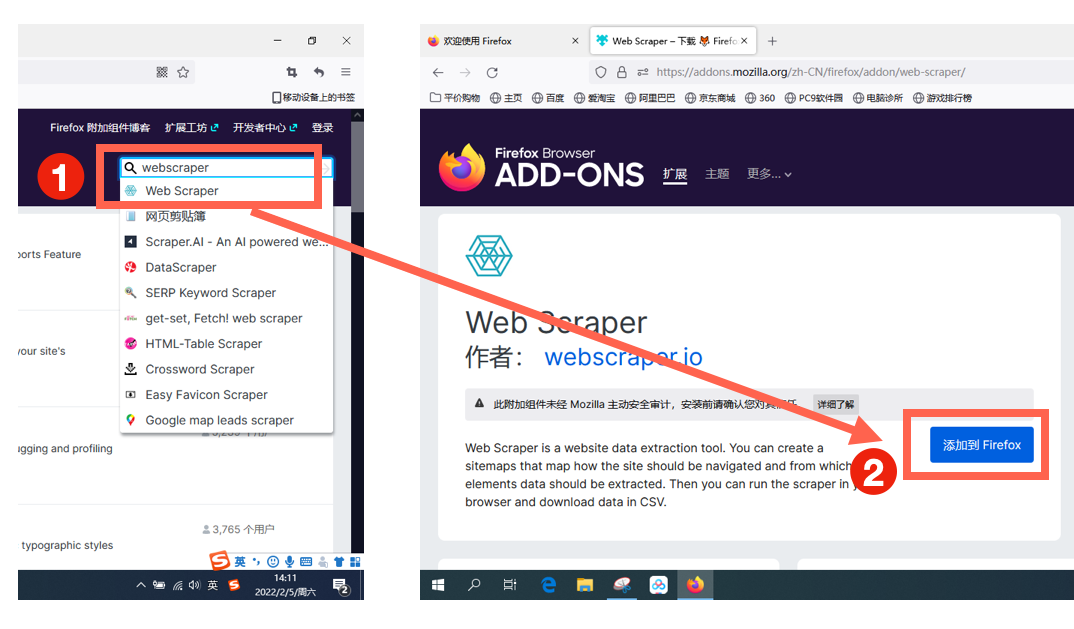
进入插件页面之后,在右上角搜索栏里,搜索“Web Scraper”,点击下拉菜单中的搜索结果,跳转到安装页面,点击“添加到Firefox”进行安装。
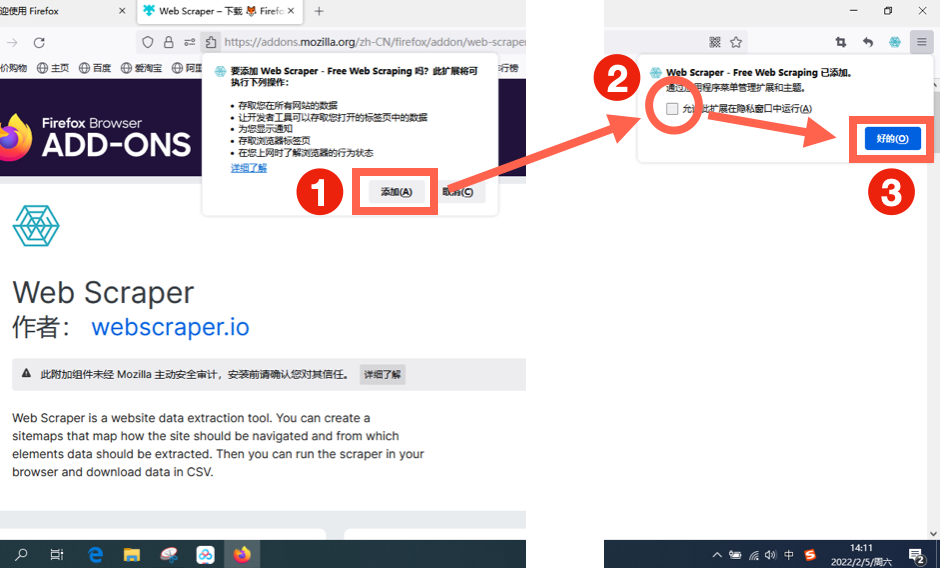
在弹框中点击“添加”,随后勾选弹框中的选项,点击“好的”完成安装。
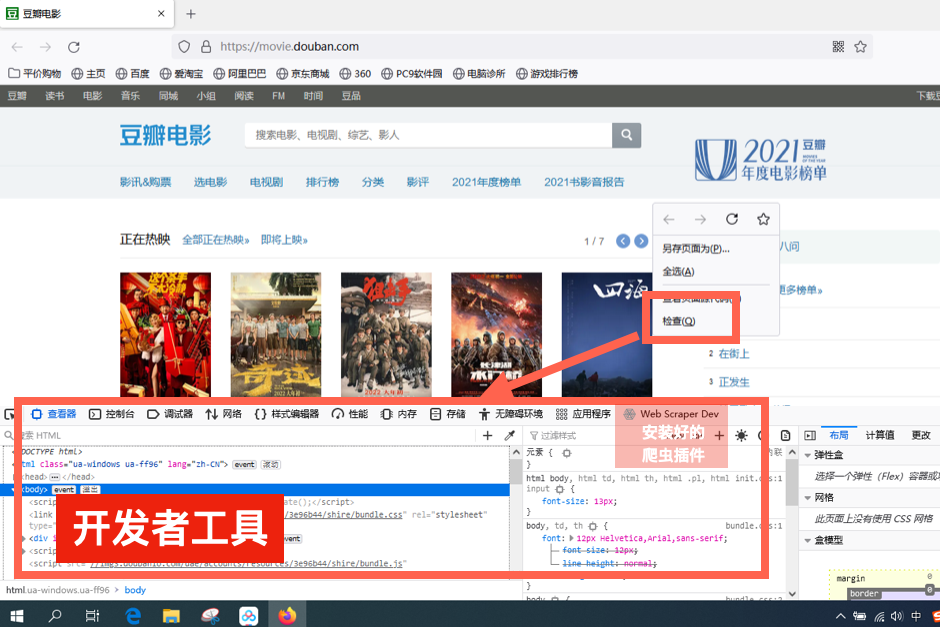
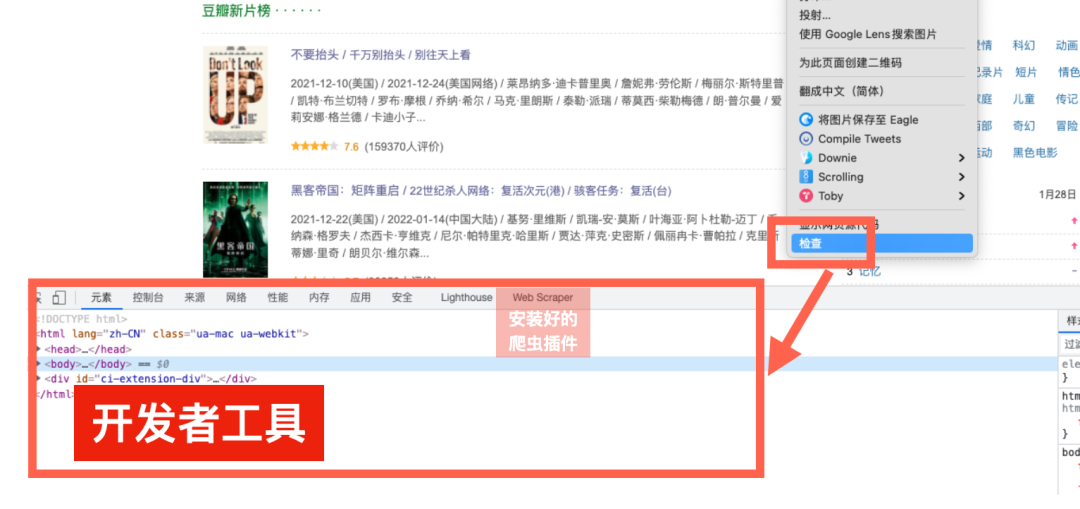
在浏览器中打开任意网页,点击右键,然后选择其中的“检查”,调出“开发者工具”窗口。
“开发者工具”是我们操作爬虫的界面,里面看起来很高大上,但我们用到的不多,所以大家不必担心。
只要看到最后一栏有“Web Scraper”的标志,就说明我们已经安装好了,前期的工作已经完成。
注意:
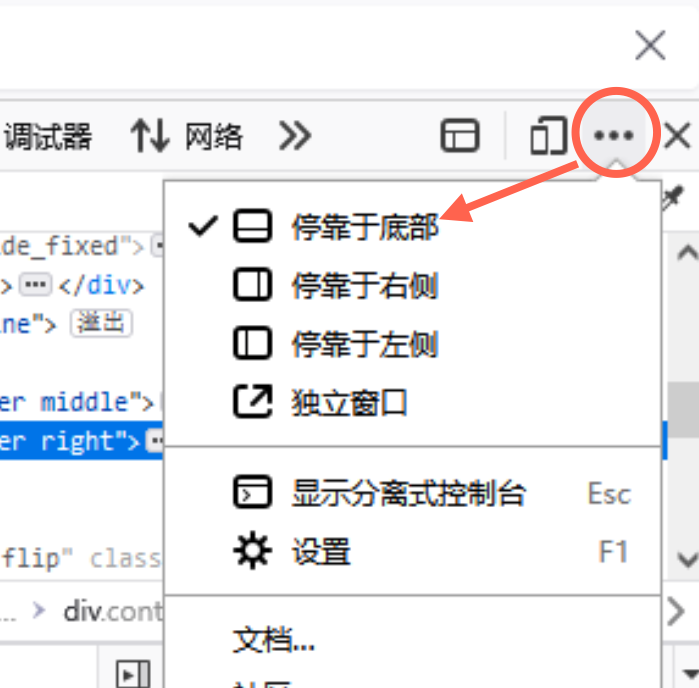
如果你调出的“开发者工具”窗口不在下方,而在侧方,可能查看不到“Web Scraper”的标志。
这时,只需要点击“开发者工具”右上角的三个点,然后选择上下分栏的停靠侧,即可把“开发者工具”的窗口,调至下方。
谷歌浏览器
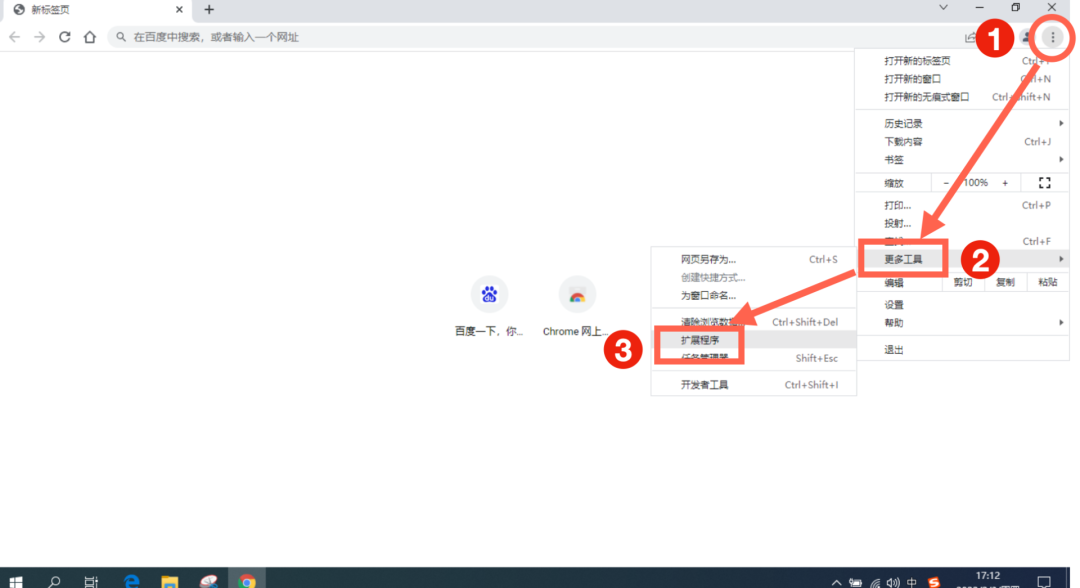
安装好浏览器之后,打开浏览器,选择右上角的三个点,选择“更多工具”,然后选择“扩展程序”。
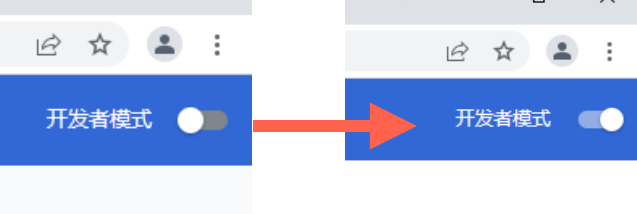
将右上角的“开发者模式”点开。
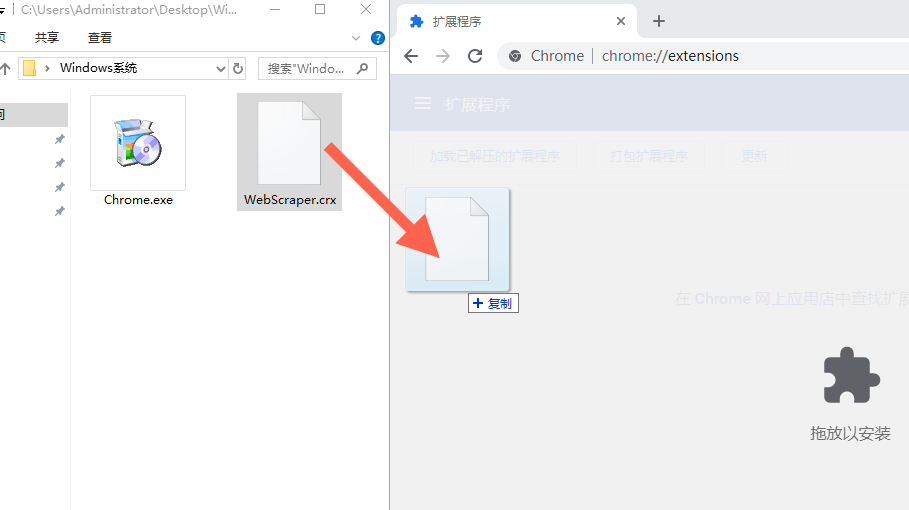
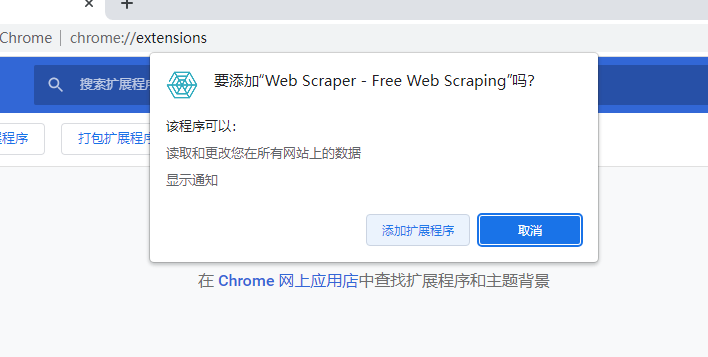
随后在刚才下载的“爬虫资源”文件夹中找到WebScraper.crx,拖拽到浏览器窗口中,并点击“添加扩展程序”完成插件的安装。
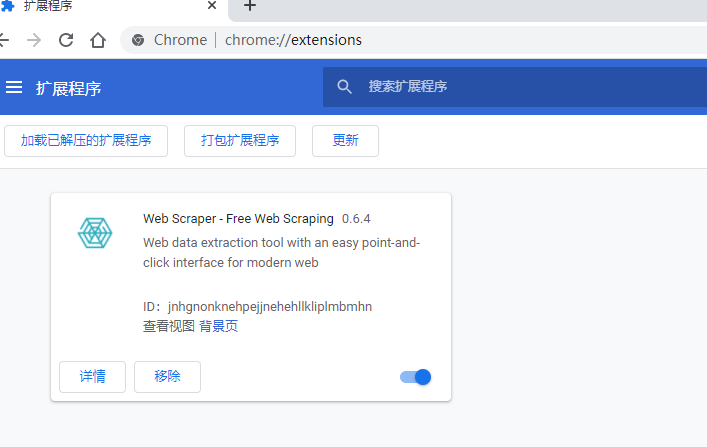
同火狐浏览器一样,打开任意网页后,点击右键,然后选择其中的“检查”,调出“开发者工具”窗口。
只要看到最后一栏有“Web Scraper”的标志,就说明我们已经安装好了。
注意:
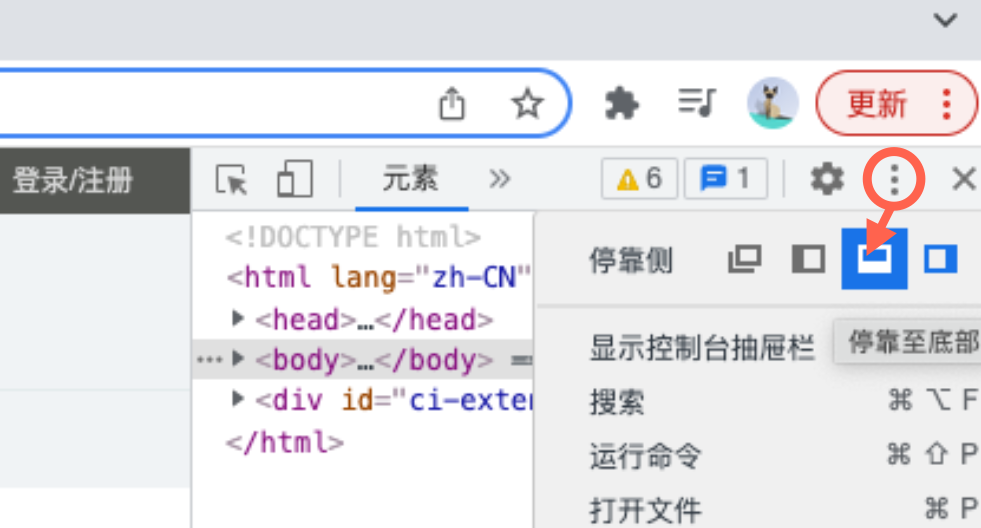
如果你调出的“开发者工具”窗口不在下方,而在侧方,可能查看不到“Web Scraper”的标志。
这时,只需要点击“开发者工具”右上角的三个点,然后选择上下分栏的停靠侧,即可把“开发者工具”的窗口,调至下方。
提示:
建议大家还是学会如何访问谷歌,这样不光能减少很多不必要的麻烦,而且还能获取更多资源(比如YouTube上的优质教程等)。
关于如何访问谷歌,我在网盘的资料中也附加了相应的方法,大家下载的时候,可以参考使用。
不同的系统,只在浏览器安装过程略有差别。
后续的所有操作都将在浏览器当中进行,所以系统差异可以忽略不计,我将使用苹果系统下的谷歌浏览器作为示范。
快速体验爬虫
在开始后续的教学步骤之前,我们可以先来体验一下,这个工具在运转时的状态。
我准备了几个已经编辑好的爬虫规则,大家可以拿过来直接用。
在刚才打开的“开发者工具”中,点击Web Scraper,可以看到软件的界面。
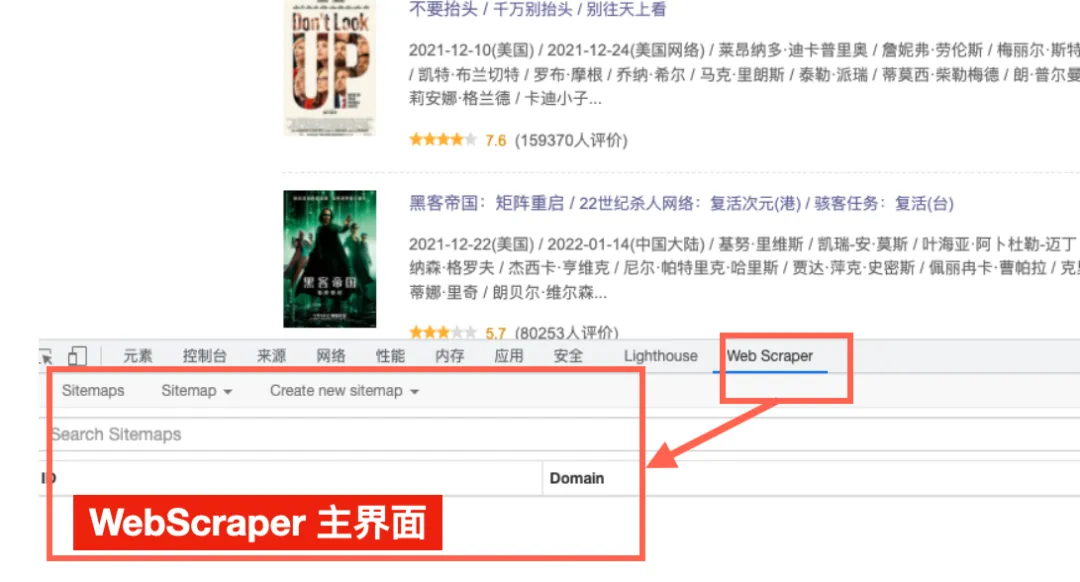
点击 “Create new sitemap”, 选择“Import Sitemap”,随后出现如下界面。
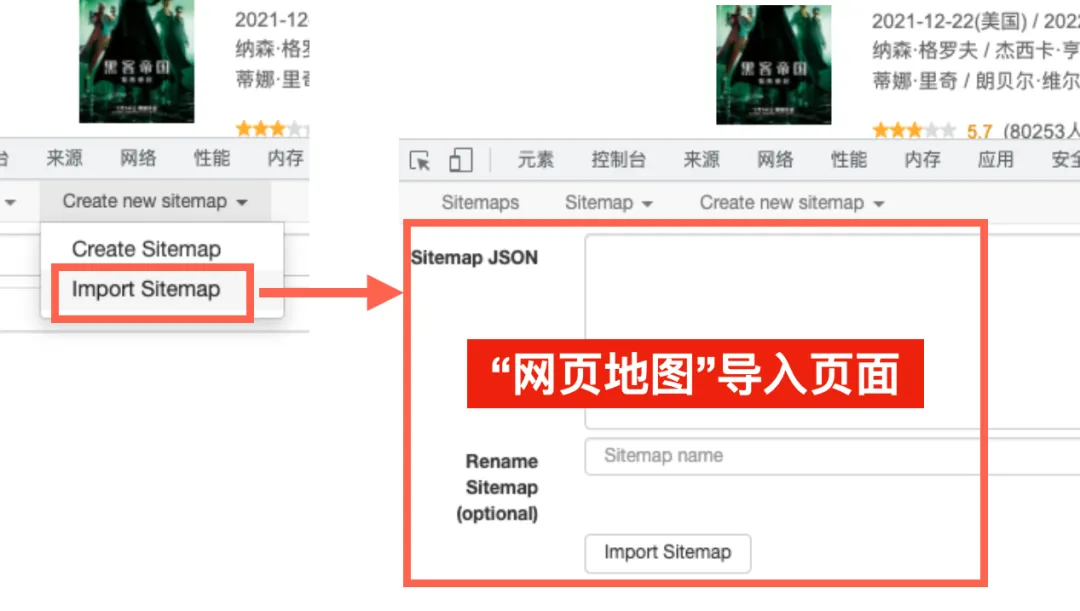
在之前下载的“爬虫资源”文件夹中,有一个import文件夹,里面就是已经编辑好的爬虫规则,我们称之为“网页地图”。
大家可以打开任意一个文档,把里面的内容复制粘贴到“Sitemap JSON”对话框里,并给它任意取个名字(三个英文字母以上),随后点击“Import Sitemap”。
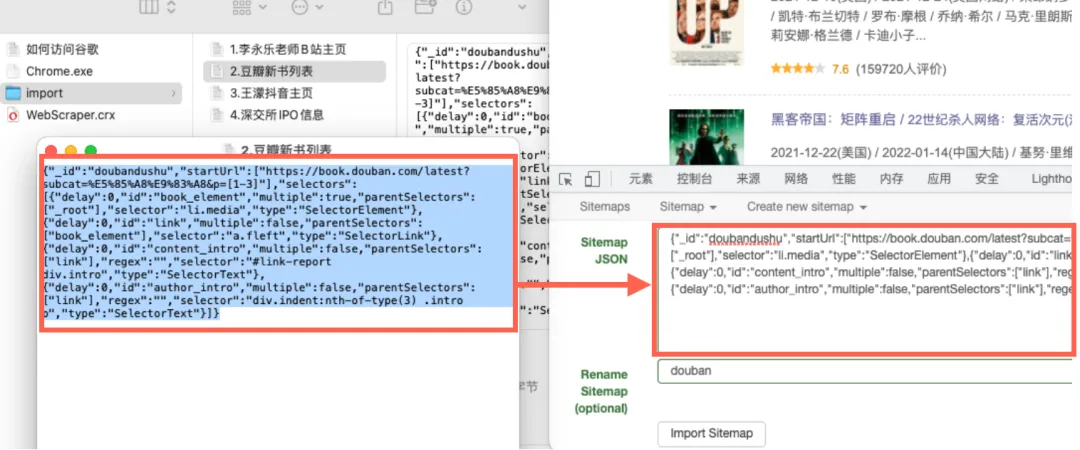 (以“豆瓣读书列表”为例)
(以“豆瓣读书列表”为例)
随后,界面会跳转到这个地图的内部,我们暂时不用管。
点击界面中的第二栏“Sitemap xxx”(这里的xxx应该会显示你刚才保存的名称,我取的是douban),选择其中的Scrape。
出现两个时间的设定,使用默认值即可,然后点击“Start Scraping”。
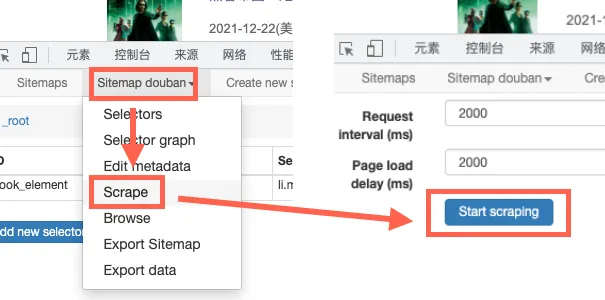
随后你就会看到,电脑新建了一个浏览器,并且开始自己爬取网页的内容了。
爬取结束后,刚才弹出的浏览器会自动关闭。
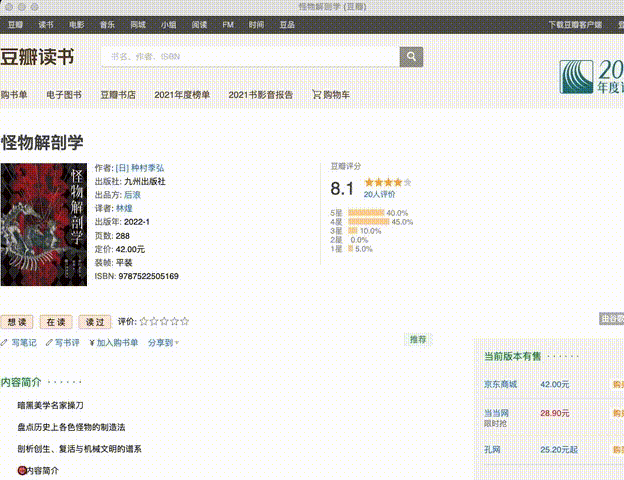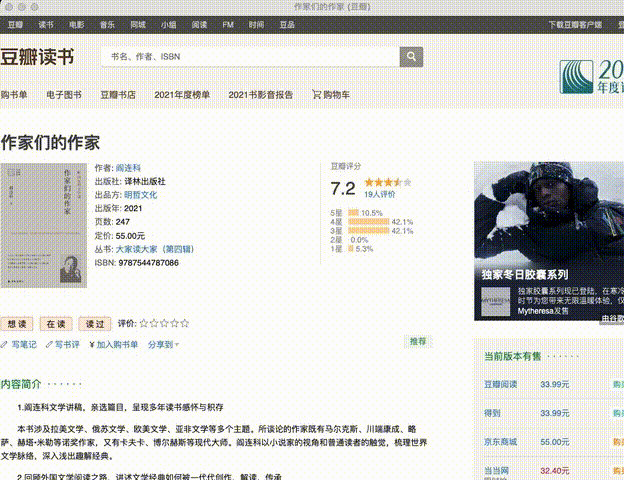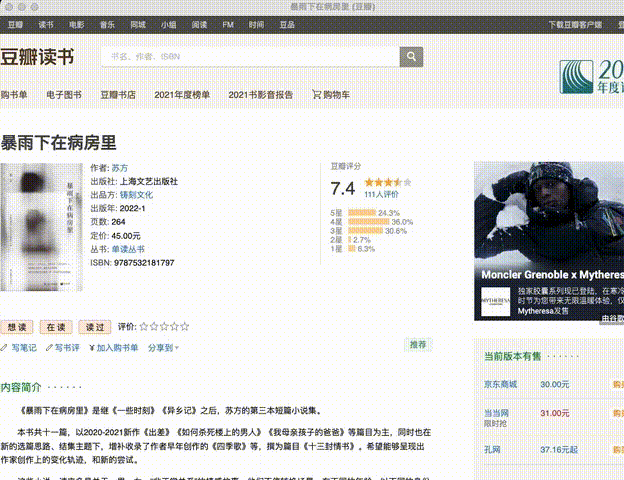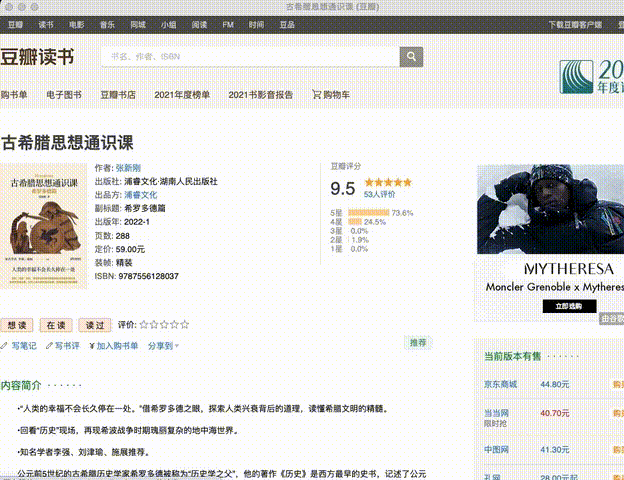 (倍速播放爬取过程)
(倍速播放爬取过程)
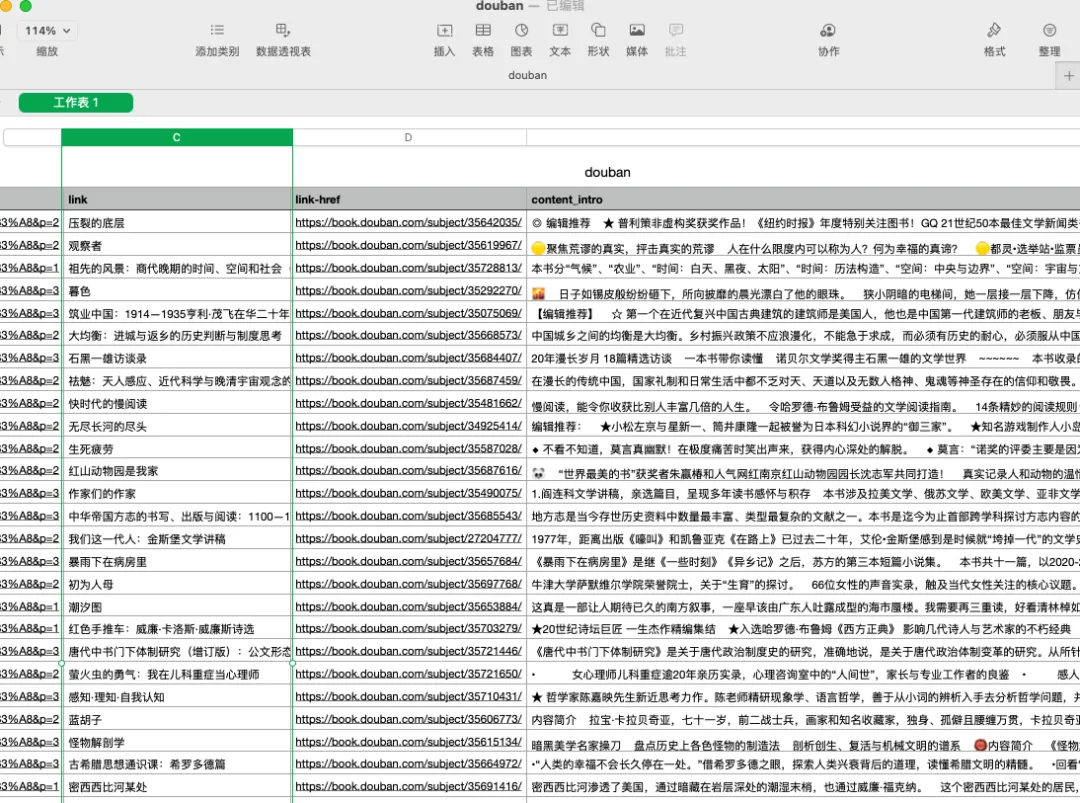
你可以点击界面中出现的“refresh”键,刷新一下,查看刚才爬取的结果。
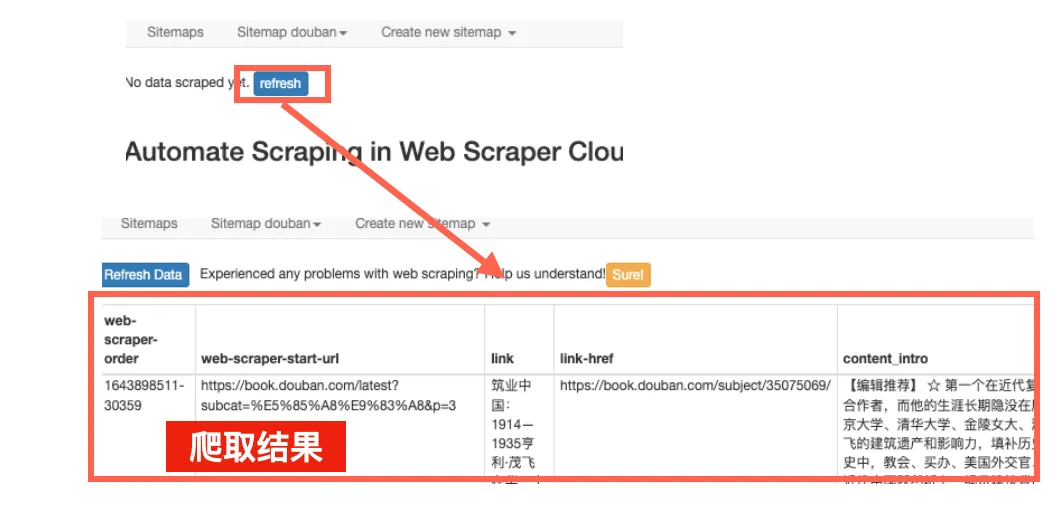
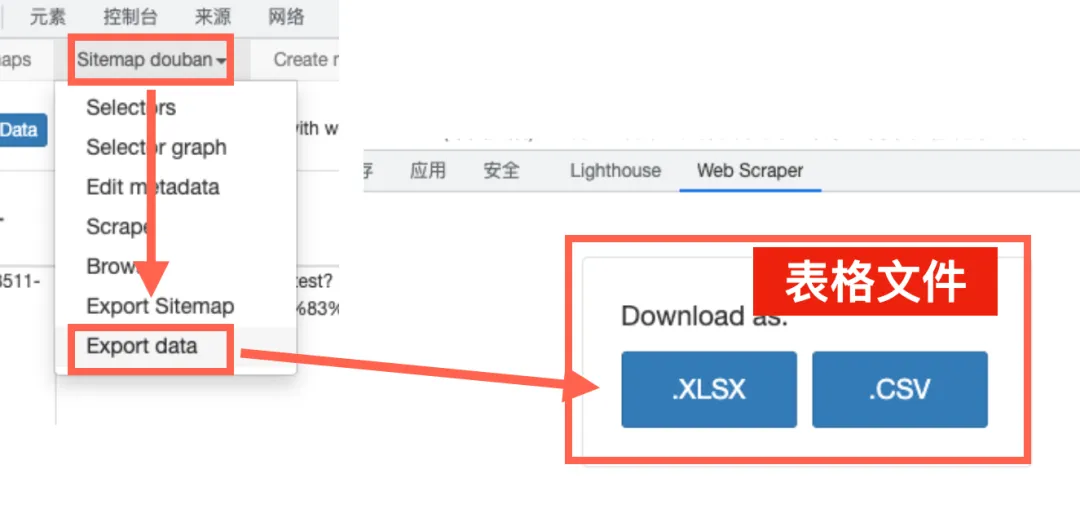
还是点击界面中的第二栏“Sitemap xxx”,选择“Export Data”,选择其中的任意格式,就能把爬取的内容下载成文件了(都是表格形式)
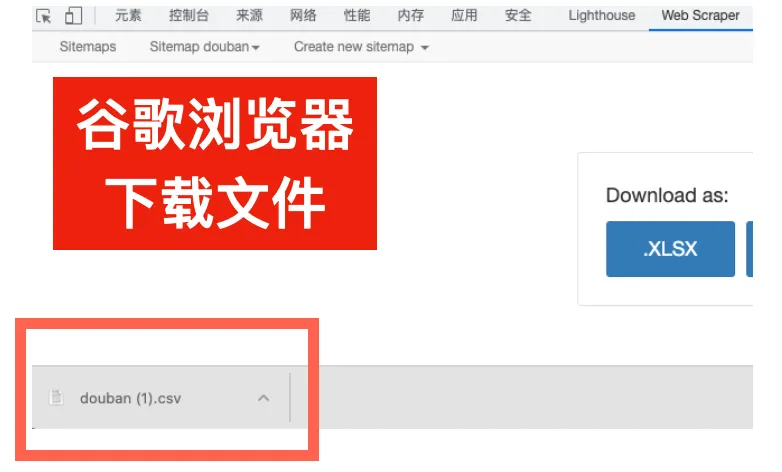
在谷歌浏览器中,下载的文件会自动出现在窗口底部,点击即可打开。
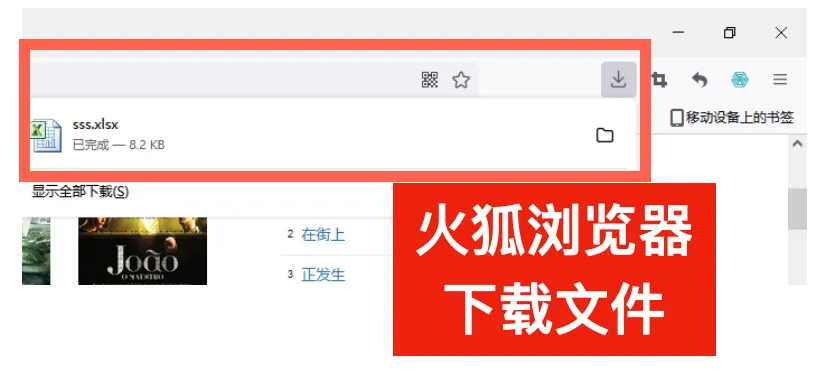
在火狐浏览器中,下载的文件会在右上角的下载图标中,点击后可以查看。
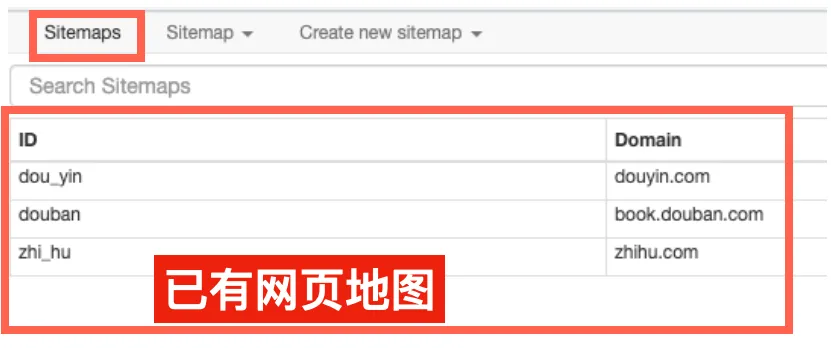
网盘文件中存放了几个不同的“网页地图”,大家可以按照上述流程,都拿过来试试。
所谓“网页地图”,就是我们给爬虫下达的指令,告诉它我们需要在哪些网站,按照什么规则,去爬取什么内容。
创建好的“网页地图”会被收藏在第一栏的“sitemaps”中,方便后期的调用和修改。
我们后面的教学,就是围绕着如何创建这种“网页地图”展开的。
这些看起来复杂的“网页地图”,其实都是电脑后期自动生成的,我们需要做的只是点点鼠标而已,大家不必担心。
因为我不是专业的程序员,所以专业的东西我也不太懂。
不过这反倒可以成为一个优势:
1.我能站在新手的角度,用小白能听懂的话,尽量把事儿说清楚。2.只把教程做到“够用”的程度,让读者能真正用起来。
所以不管是这个爬虫的教程,还是后续的编程系列教程,都会遵守这个原则来编排。
预告:下一篇我们讲解下Web Scraper的基础框架。
在基础框架上,稍加变形,就可以应对几乎所有的爬虫情况,所以掌握这部分内容还是挺重要的。